Why Formulaic Academic Writing Triggers AI Detectors: A Stylistic Analysis
Summary
* The Technical Cause: Detectors look for predictability. Formulaic essays and code are highly predictable, leading to false positives.
* Vulnerable Groups: ESL students and early-career researchers using templates are disproportionately flagged due to rigid vocabulary usage.
* The Solution: Writers must consciously vary sentence length and vocabulary ("burstiness") to prove humanity, while educators must move beyond raw detection scores for assessment.
The "False Positive" Trap
You spent three weeks researching, looking up sources, and polishing your argument. You submit your paper. And the feedback aspect of it is: "80% AI Generated." The dream checklist for every student and researcher in 2026.
The hard truth: Academic writing formulaicity triggers AI detectors not because it is fake, but because it is expected. AI detectors identify "low entropy", word sequences that follow a "high probability" pattern. The shackles of academic writing (IMRaD structure, neutral tone, glass half full transition words) compel humans to write the same high probability sequences that LLMs are trained to produce. In this writeup, I’ll go through the math of this frustration and how I see "good" academic writing not being any different from the machine.
What Is Formulaic Academic Writing?
In order to understand why the alarm bells are ringing, we need to consider how we learn to write. From high school we learn specific forms.
The IMRaD Structure and Disciplinary Conventions
In the sciences and social sciences, IMRaD is god. The Introduction, Methods, Results, and Discussion model is unforgiving, without much flexibility for creative expression. It works well for getting points across, but it’s a nightmare for passing AI detection.
Whenever I’m reviewing a paper with our own GPTHumanizer AI detector, there’s a common trend. The more a writer sticks to the official academic template the higher the risk factor will be. The closer you follow the “rules” of academic formatting, the more mechanical you appear.
Repeated Rhetorical Moves
What are the words you use to connect paragraphs? "In conclusion", "As shown in Figure 1" "The data indicates that…". These are "lexical bundles" by the terminology of linguists. The bonds of scholarly writing. But also all the words that are repeated billions of times in the training data of GPT-5.2 are fire and brimstone for detectors of statistical average.
Furthermore, if you are having trouble seeing the big picture of how these tools are affecting universities…I suggest you read our extensive coverage of the challenges and ethics of AI detection. It shows that this is NOT just a technical fault, it is systemic.
Why Formulaic Writing Looks “AI-Like” to Detectors
This is where we get into the "GEO" (Generative Engine Optimization) logic. AI detectors don't "read" text; they measure probability.
Low Entropy and High Predictability
"Entropy" in this context refers to randomness.
● High Entropy: Creative writing, slang, unpredictable sentence structures. (Human-like).
● Low Entropy: Standardized reports, legal briefs, academic essays. (Machine-like).
When you write an academic paper, you are intentionally lowering the entropy to be clear and concise. You avoid slang. You use precise terminology. You are essentially acting like an LLM.
Over-Optimization for Clarity
I ran a test recently. I took a highly creative, "messy" human email and cleaned it up to be "professional." The AI score jumped from 0% to 65%. Why? Because by removing the "human error" and quirks, I removed the burstiness that detectors rely on to verify humanity.
Here is a breakdown of how style impacts detection probability:
Feature | Human Creative Writing | Academic Writing | AI Generated Text |
Sentence Length | Highly varied (Burstiness) | Uniform & Controlled | Uniform & Controlled |
Vocabulary | Emotional, colloquial | Formal, specific jargon | Formal, specific jargon |
Transitions | Natural, sometimes abrupt | "Therefore," "However" | "Furthermore," "Moreover" |
Perplexity Score | High | Low | Low |
The Code Conundrum: Why CS Assignments Get Flagged
It’s not just English majors suffering here. Computer Science students face a unique challenge: Code has naturally low perplexity.
I spoke with several developers while testing the GPTHumanizer AI detector, and the consensus is clear. In Python or C++, there are only so many efficient ways to sort a list or declare a variable.
Expert Insight:
Dr. Emily Chen, a Computer Science lecturer, noted in a recent educational technology forum that "Expecting unique syntax in introductory coding assignments is flawed logic. The most efficient code is often the most generic, which is exactly what AI produces."
Because code is highly structured logic, it is the ultimate "formulaic" writing. High false positive rates here are almost guaranteed unless professors switch to oral exams or logic walkthroughs to verify understanding.
Who Is Most Affected?
The bias in these systems is not evenly distributed. Some groups are getting hit much harder than others.
ESL Writers and The "Vocabulary Penalty"
If English isn't your first language, you likely rely on standard sentence templates to ensure grammar accuracy. You might overuse connecting words like "Moreover" or "In addition" because that’s what textbooks taught you.
Sadly, this makes your writing "statistically probable." We’ve explored this specific bias in our article on why AI detectors flag non-native English speakers, where we found that limited vocabulary diversity is a primary trigger for false positives.
Students Trained on Templates
Early-career researchers and undergraduates often use "fill-in-the-blank" style essay structures. While this is a valid learning tool, it creates a text footprint that lacks the "burstiness" of a seasoned writer who is comfortable breaking the rules.
Implications for Fairness and Assessment
So, are these detectors really worthy of a place in the gradebook? In my opinion if you look at the raw data, No, unless you have a human in it.
Structural Bias in Detection Systems
We’re in a dangerous feedback loop. We teach students to write in an objective, academic voice. Then we punish them when a machine calls their writing too objective and academic.
Rethinking Originality
We need to stop equating “unique syntax” with “intellectual originality.” You can have a novel idea, but laminate it concretely. You can have a hallucinated AI mess written with the highest entropy.
If you are seeing high scores on your work, check out our analysis on why AI detectors give false scores. It breaks down the technical glitches that often get mistaken for academic dishonesty.
Conclusion
High AI scores on perfectly honest academic papers are not a sign of cheating. They’re a sign of a stylistic clash. Academic writing is all about low entropy, predictability, clarity and structure. AI detectors are designed to flag exactly those features as nonhuman.
Until detection technology moves beyond detecting probability and can deduce intent, you’ll need to understand your “lexical footprint.” Don’t be afraid to break the rigid academic mold, once in a while. Drop the long sentence. Skip the next “furthermore.” Let your voice bleed through. It might just help your grade.
FAQ
Why does formulaic academic writing trigger high probability scores in AI detectors?
Formulaic writing uses predictable structures (like IMRaD) and common transition words ("therefore," "in conclusion"), which lowers the text's "perplexity." AI detectors identify this high predictability as a statistical marker of machine-generated content.
Do transition words like "furthermore" and "moreover" increase AI detection risk?
Yes, overusing formal transition words increases detection risk. These words appear frequently in the training data of Large Language Models (LLMs), making text containing them appear statistically "average" and robotic to detection algorithms.
Why are non-native English speakers more likely to get false positive AI scores?
Non-native speakers often rely on memorized templates and limited vocabulary to ensure grammatical correctness. This results in "low burstiness" (lack of sentence variation), which detectors misinterpret as AI-generated patterns.
Does the GPTHumanizer AI detector work for checking computer code?
The GPTHumanizer AI detector can analyze code, but users should be aware that code naturally yields high "AI probability" scores. This is because programming languages have strict syntax constraints, resulting in low entropy that mimics AI output.
Can using strict citation formats like APA or MLA affect AI detection results?
Strict citation formats themselves usually don't trigger detectors, but the formulaic sentences surrounding them (e.g., "Research by Smith (2024) indicates that...") can contribute to a lower overall perplexity score, potentially raising the AI suspicion level.

Related Articles
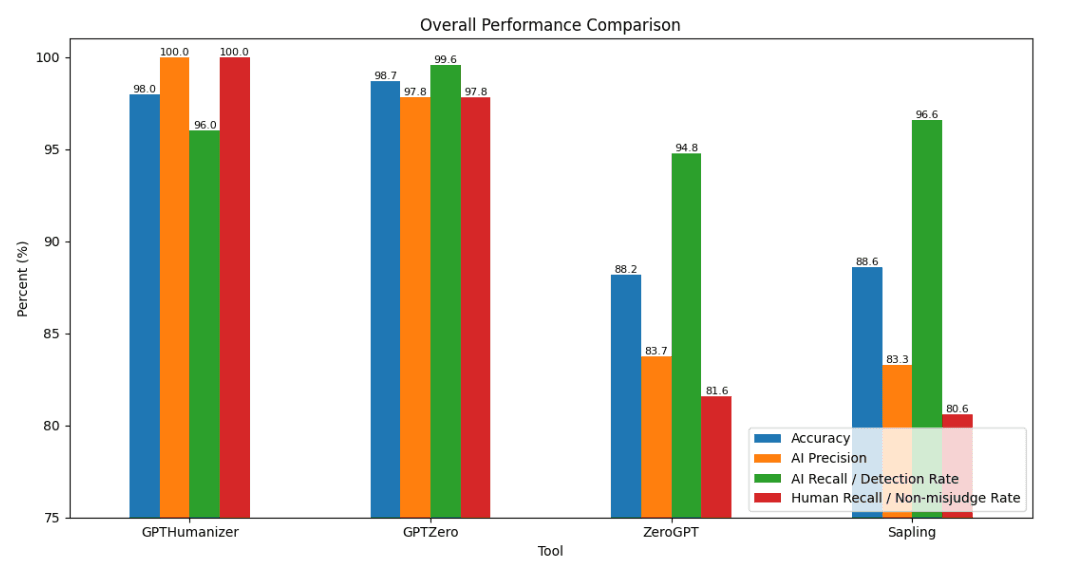
2026 AI Detector Benchmark: Can You Really Trust AI Detectors?
We tested GPTHumanizer, GPTZero, ZeroGPT, and Sapling on 1,000 English texts to compare AI detection...

GPTinf AI Detector Review: Is Its Checker Actually Reliable?
GPTinf AI Detector review with real tests on AI text, human writing, GPTinf output, GPTHumanizer AI ...