The Technical Evolution of AI Humanizers: From Paraphrasing to Neural Editing (2026)
Summary
Modern AI humanizers are no longer just paraphrasing tools that swap words until a paragraph looks different. The real technical shift is from surface-level variation to controlled neural editing that improves rhythm, tone, and readability while preserving meaning, facts, and structure.
This article explains how that shift happened, why synonym-based rewriting breaks down so easily, and what a stronger humanization pipeline looks like in practice. It also shows why modern evaluation should focus on fidelity, information integrity, readability, and controllability together, instead of over-trusting a single detector score.
In GPTHumanizer AI, that shift shows up in a very practical way. The product is designed to refine text at the sentence and paragraph level, apply different levels of editing depending on how much a draft really needs, and improve flow without casually changing the original meaning, tone, or intent. That matters because a real humanizer should feel like a controlled editing system, not a one-click paraphraser that pushes every draft in the same direction.
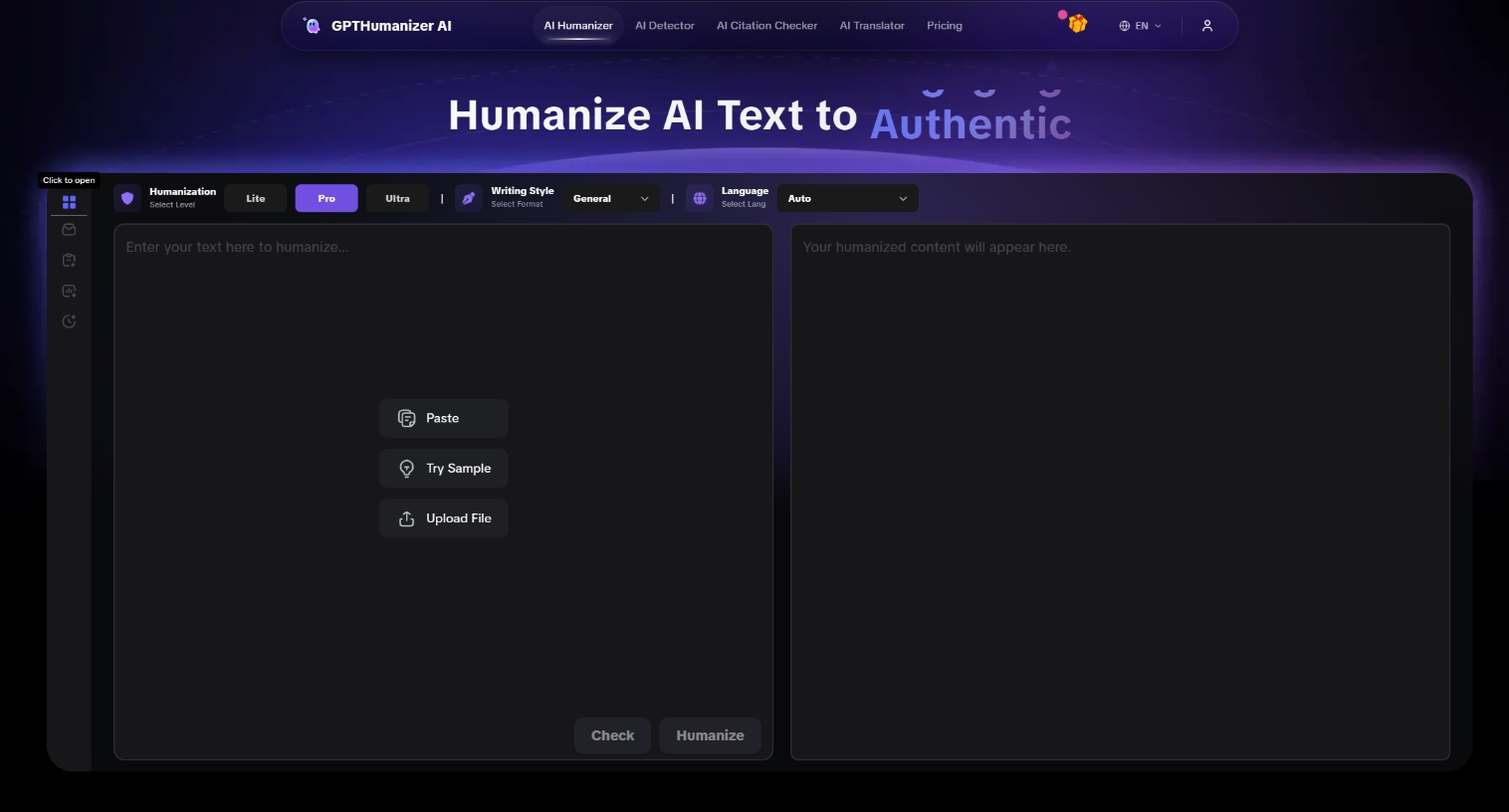
Modern AI humanization techniques are no longer about swapping words until a paragraph looks different. The stronger systems in 2026 behave more like controlled editing stacks: they preserve meaning, protect numbers and terms, adjust rhythm and structure, then verify that the draft still says what it originally meant.
That is the real technical shift from paraphrasing to neural editing. A serious AI humanizer is not a synonym spinner and not a disguise tool. It is an editing system designed to make AI-flat writing more natural, more readable, and more publishable without casually breaking facts, tone, or structure.
What an AI humanizer actually is
An AI humanizer is best understood as an editing workflow, not a content generator. It starts with an existing draft and improves how that draft reads. The job is not to invent new ideas. The job is to reduce robotic phrasing, repetitive structure, stiff transitions, and context-blind wording while keeping the original point intact.
That is why the better humanizers do not behave like one-shot rewriters. They behave more like layered editors. They identify what must stay fixed, rewrite only where the draft sounds flat or unnatural, then run a final check for meaning, structure, and fluency.
That is also the right way to understand GPTHumanizer AI. It starts with an existing draft, not a blank page, and the goal is not to make the text look dramatically different for its own sake. The goal is to make it read more naturally by improving phrasing, rhythm, and structure in a controlled way. That is why meaning preservation, tone control, and rewrite depth matter so much more than surface-level variation.
Why synonym swaps stopped working
The earliest generation of “humanization” tools mostly relied on lexical substitution. In plain English, they changed words more than they changed writing. That was enough to make a paragraph look different, but not enough to make it sound convincingly natural.
The problem becomes obvious in technical, academic, or structured writing. Terms are not decoration. Numbers are not decoration. Headings, lists, Markdown, and citations are not decoration either. A system that treats all of that like optional surface text will quickly damage precision, weaken claims, or flatten the draft into generic prose. That is where the shift from paraphrasing to neural editing really matters. A paraphraser mainly aims for surface variation, while a stronger humanizer has to preserve meaning, protect key details, respect structure, and still improve rhythm and voice.
What synonym tools miss is that weak writing does not break at the word level only. It breaks at the level of claims, terms, and structure. A sentence can still sound smooth after rewriting while quietly changing what it really says. “Causes” becomes “is associated with.” “Will” becomes “may.” “Proves” becomes “suggests.” The paragraph may look cleaner on the surface, but the original claim is no longer the same claim. The same problem shows up with technical language, where terms carry specific meaning and cannot be treated as interchangeable style choices just because the system wants more variation.
Structure matters just as much. Lists, headings, citations, formatting, and parallel phrasing are part of how the text communicates, not extra decoration around it. If a tool only swaps tokens without respecting those relationships, the output may look different while becoming less useful. That is the deeper reason synonym swaps stopped working. The real evolution was not just “more rewriting,” but better control: modern systems moved away from blind substitution and toward context-aware, structure-aware editing.
How modern AI humanizers actually work
A modern AI humanizer is not one algorithm. It is usually a controlled editing stack made of several layers.
1. Intent and context routing
The system first needs to know what “better” means for this draft. Human writing does not have one universal style. Academic writing needs caution and precision. Marketing needs stronger cadence and voice. Technical writing needs consistency and structure. So the first job is to identify audience, tone target, rewrite depth, and risk tolerance.
This is also why style control matters in a serious product. A blog post, a follow-up email, and a landing page should not all be rewritten with the same pressure just because they started as AI-generated text. In GPTHumanizer AI, style and tone control make sense for exactly this reason: the system needs a clearer target before it can decide what should be softened, what should be tightened, and what should stay untouched.
The same logic applies across languages too, because natural rhythm, sentence density, and acceptable phrasing patterns do not stay identical from one language to another.
2. Constraint locking
Before rewriting begins, the system should identify what must not change. That includes entities, numbers, dates, product names, technical terms, and any structural elements that carry meaning. This step is boring, but it is where serious tools separate themselves from flashy demos.
3. Multi-stage rewriting
The strongest systems do not try to solve everything in one pass. They usually improve the draft in layers: first reducing repetitive phrasing, then smoothing transitions, then adjusting sentence rhythm, and only then applying stronger voice or style changes where needed. This is what makes the output feel edited rather than randomly rewritten.
That layered logic also explains why different rewrite depths are useful in practice. Some drafts only need a lighter cleanup to remove stiffness and obvious repetition. Others need deeper sentence and paragraph-level reshaping before they sound natural enough to publish. This is the thinking behind GPTHumanizer AI’s Lite, Pro, and Ultra modes. Treating every draft as if it needs the same level of intervention is one of the reasons weaker tools feel uneven and unpredictable.
4. Low-risk final polish
Even after the main rewrite, a draft can still feel slightly off. This is where lightweight grammar and fluency correction matter. The goal here is not to regenerate the paragraph again. The goal is to fix the last small issues without introducing meaning drift.
5. Verification before acceptance
A serious humanizer does not stop at “the output sounds good.” It checks whether the meaning stayed stable, whether key facts survived, whether the structure is still usable, and whether the rewrite depth matches the original intent. If the answer is no, the system should revise more carefully, not just rewrite more aggressively.
This is also where a built-in detector can make sense, as long as it is treated as a review signal rather than the goal of the rewrite. In GPTHumanizer AI, that kind of check is most useful when it sits alongside meaning retention, readability, and structural review. It can help flag drafts that still feel too flat, too repetitive, or slightly off in tone, but it should never replace human judgment or become the only success metric.
Where humanization helps — and where it fails
AI humanization works best when the draft already has a real point and only needs better expression. In that situation, it can reduce stiffness, improve transitions, smooth sentence rhythm, and make the wording feel more natural for the intended context. It is especially useful when the ideas are already sound but the phrasing still feels flat, repetitive, overly uniform, or slightly too “generated” in cadence.
It is much less reliable when people expect it to solve the wrong problem. If the original draft is vague, poorly structured, factually weak, or full of logical gaps, humanization does not fix that foundation. It can improve presentation, but it cannot invent clarity that was never there in the first place. The same limitation applies when the text depends on precision. In technical, academic, legal, or highly structured writing, careless rewriting can blur claims, soften key distinctions, or damage formatting that actually carries meaning.
That is why good humanization should be understood as editorial improvement rather than unrestricted rewriting. The strongest systems help a draft read more naturally while still keeping the original point intact. Once the tool starts overwriting meaning, flattening important structure, or pushing every paragraph into the same generic voice, the process stops being useful and starts becoming distortion.
How to evaluate a humanizer without over-trusting one score
Most weak evaluations collapse everything into one number. That is the wrong instinct. A lower detector score does not automatically mean better writing. Higher variation does not automatically mean stronger editing. Better readability does not automatically mean the draft stayed accurate.
A more useful evaluation framework asks four questions:
1. Did the meaning stay stable?
The central claim, stance, and level of certainty should still match the original draft.
2. Did the important details survive?
Numbers, entities, product names, domain terms, dates, and document logic should remain intact.
3. Did the writing actually improve?
The output should read more naturally, with better cadence, smoother transitions, and less generic phrasing.
4. Was the level of editing appropriate?
A light polish should stay light. A deeper rewrite should still feel controlled. Editing depth should be a dial, not a coin flip.
That is the real standard: fidelity, information integrity, readability, and control together.
A more useful standard is a multi-dimensional evaluation framework that looks at fidelity, information integrity, readability, and control together. And when people over-focus on detector outputs, they usually need a better explanation of perplexity and burstiness first.
What still goes wrong in 2026
Even the better humanizers still fail in predictable ways.
Over-editing
The system makes the draft sound “different” at the cost of sounding less precise, less credible, or less like the original writer.
Meaning drift
Facts survive on paper, but the strength of the claim changes. Causality becomes correlation. Specificity becomes vagueness. This is one of the most common hidden failures.
Trust gaps
Users care about more than output quality. They also care about whether the tool handles sensitive drafts responsibly, whether the changes are explainable, and whether the system makes review easier rather than harder.
In a real product, that trust question goes beyond output quality. It also includes privacy, responsible use, and whether the workflow still leaves the final reviewer in control. That is part of why serious humanization should be explained as an editing process rather than a magic transformation. If a tool talks only about sounding more human but says nothing about review, user control, or sensitive content handling, the technical story is incomplete.
Conclusion
The technical evolution of AI humanizers was not a move toward heavier rewriting. It was a move toward better control.
The modern standard is simple: preserve meaning, protect important details, improve readability, and keep the draft usable. That is what separates a real humanizer from a paraphraser, and that is why neural editing matters more than word substitution in 2026.
If you want to see what that looks like in practice, the easiest way is to compare a shallow rewrite with a controlled one. That is exactly where GPTHumanizer AI is useful: not as a gimmick layer on top of AI writing, but as a more structured way to make a draft read naturally without losing the point it started with.
FAQ
What is the difference between an AI humanizer and a paraphraser?
An AI humanizer is supposed to improve how a draft reads while preserving meaning, facts, and structure. A paraphraser mainly focuses on changing wording. The real difference is not whether the output looks different. It is whether the draft becomes more natural without becoming less accurate.
Why do synonym-swap tools often weaken technical writing?
Because technical writing depends on exact wording, stable claim strength, and intact details. A synonym-swap tool may make the sentence look different, but it often softens causality, removes precision, or replaces domain terms with vaguer language.
How does a modern AI humanizer preserve meaning during rewriting?
A stronger humanizer usually works like an editing pipeline. It identifies the target tone, protects critical details such as entities and numbers, rewrites in controlled stages, and then checks whether the meaning and structure still hold.
What should be measured when evaluating AI humanization quality?
A useful evaluation should look at four things together: meaning preservation, information integrity, readability and flow, and output controllability. Looking at only one score usually leads to the wrong conclusion.
Do lower AI detector scores prove that the writing is better?
No. A lower detector score does not automatically mean the text is clearer, more faithful, or more publishable. Detector signals can be useful for review, but they should not be treated as the final quality standard.
Does neural editing mean rewriting everything from scratch?
No. Neural editing is valuable because it can improve rhythm, tone, and structure without forcing a full rewrite. The best systems behave more like careful editors than one-shot rewriters.

Related Articles
HIX Bypass Pricing Explained: Is It Worth Paying For in 2026?
A practical look at HIX Bypass pricing, paid-plan value, word limits, refund terms, and whether it i...
Does Hixbypas Work in 2026? Fast, and Aggressive Modes Tested
Does Hixbypas, or HIX Bypass, actually work? I tested Fast and Aggressive modes to compare rewrite q...
Best HIX Bypass Alternative: Free, No-Sign-Up AI Humanizer Compared
Looking for a HIX Bypass alternative? Compare HIX Bypass with GPTHumanizer for free access, no-sign-...
StealthGPT AI Review 2026: Features, Pricing, Output Quality, and Alternatives
I reviewed StealthGPT AI across pricing, features, rewrite quality, and real writing use cases. See ...