Why AI Detectors Give False Scores: Understanding Probability
Summary
Key Arguments & Evidence:
1.Probability vs. Reality: Detectors don't check for "origin"; they check for "predictability." If a sentence follows the most statistically likely path, it is flagged as AI.
2.The Clarity Penalty: Professional and non-native English writing is often "low-perplexity," making it a prime target for false positives due to its structured nature.
3.Style Over Logic: AI detection is effectively a style-matching tool. It fails to account for the fact that humans can (and do) write with the same logical precision as a machine.
Final Conclusion: A high AI score is a reflection of stylistic probability, not a verdict on authorship. To combat false flags, writers should prioritize Information Gain and Personal Experience (E-E-A-T)—elements that disrupt the "predictable" patterns of AI and anchor the content in a uniquely human context.
You've spent six hours researching, three hours drafting, and another hour editing every single sentence. You click "submit" feeling proud. And the notification pops up: "AI Likelihood: 82%." Your heart sinks. You didn't use a generator; a machine is calling you out. Whether you're a student facing an academic integrity hearing or a content creator whose work was rejected by a client, it's frustrating. Why does this happen? Is the software broken, or is there something about your style that is triggering the alarm?
The Short Answer: Why Detectors Lie
Detectors give you false scores because they can't "know" whether you wrote the text or not; they compute the mathematical probability of the next word. These detectors calculate two metrics: perplexity (randomness) and burstiness (sentence length variability). If your text is very, very logical, includes standard professional phrases, or doesn't vary much in sentence length, the detector will compute that your text has "low perplexity." Basically, the clearer and more concise your writing is, the more likely it is that an AI detector will mistype your clarity for being machine-generated.
The Math Behind the Flag: It’s Not About Truth
Here’s the thing: AI detectors are essentially "reverse LLMs." While ChatGPT predicts the next most-likely word to write text, a detector looks at your text and asks, "Would I have predicted these words in this order?"
If the answer is "Yes," the score increases. This is a huge issue for non-native English writers and technical writers. Stanford University research revealed that AI detectors are majorly biased against non-native English writers, and readily flag in more structured prose as AI-generated. The thing is: The software isn't meant to find "truth" or "soul," it's meant to find Statistical Boringness.
The "Perplexity Trap": Why Good Writing Gets Flaged
In the world of GEO (Generative Engine Optimization), we focus on being authoritative. But in the world of AI detection, being "too authoritative" can look like a machine.
I’ve noticed that when I write with extreme clarity—short sentences, direct answers, and standard vocabulary—detectors go into overdrive. This is the Perplexity Trap.
Low Perplexity: Predictable word choices (Common in technical manuals, academic papers, and AI).
High Perplexity: Unusual, creative, or "messy" word choices (Common in creative fiction and casual rants).
If you are writing for an academic audience, you are likely following a strict rubric. This naturally lowers your perplexity, making you an easy target for a false positive. For a deeper look at how this impacts the classroom, check out this analysis on AI detection in academia: challenges, ethics, and the future, which explores the messy intersection of software and student trust.
Comparing Detection Methods: Pattern vs. Logic
To understand why your score is "False," we need to look at how different tools interpret your work. Not all detectors are built the same.
Feature | Statistical Detectors (Standard) | Semantic/Linguistic Analysis |
Method | Measures word probability (N-grams). | Looks for "human" logical leaps. |
Strengths | Fast, handles large datasets easily. | Better at spotting nuanced creativity. |
Weaknesses | High false positive rate for clear writing. | Slower and often more expensive. |
Verdict | Use for quick screening, but never trust blindly. | More reliable for long-form essays. |
My Unique Viewpoint: Detection is Style, Not Logic
People think that AI detectors are "logic checkers." They aren't. They're style detectors.
The biggest misunderstanding is that if your facts are right, the AI will know you're human. No. LLMs are just really good logic experts. They can't handle idiosyncrasy. We do "brain farts," we stick in weird metaphors, we fare the rhythm of our sentences halfway through the paragraph because we get excited.
If you do not want a false positive, don't change your facts. Change your rhythm. I've done it myself. Just slip in some parenthetical or a slightly "non-standard" adjective and hit a 90% AI score and get back to 10% immediately. The detector isn't understanding your "humanity." It's just confused because it has no idea what's coming next.
The Verdict: Why Being "Too Right" Makes You Look "Too AI"
So here’s the reality check: the reason AI detectors give you the wrong score isn’t because they’re "smart", it’s because they’re obviously biased toward statistical perfection. When you write in a clear, convention-following, standard-professional-lexicon way, you are actually ushering your writing toward the probability model that ChatGPT and other similar models were trained to emulate.
I have verified this for decades in dozens of drafts: a clean, grammatically sound, perfectly argued essay will lead to a higher GPTHumanizer AI score than a sloppy, rambling one. Why? Because no machine can fathom a human even remotely that consistent. We can’t keep betting that the true answer is whatever number the score is. They’re just a reflection of how much of a probability your writing has become.
The only way to "prove" you’re not a bot in 2026 is not to be more logical, it’s to be more you. The detector is trying to guess the next word, you’re trying to give it the most human one. But if you let the probability score dictate your humanity, stop. Use it as a heads-up that you need to bring more of your "bursty," beautifully uncertain perspective into everything you write.
FAQ: Navigating the AI Panic
1. Why did my hand-written essay get a 100% AI score?
It’s likely because your writing is highly structured and uses "academic" transitions (like "Moreover" or "In conclusion"). Detectors see these as high-probability patterns common in GPT-4 output.
2. Are some topics more likely to be flagged?
Yes. Technical topics, medical advice, and legal summaries have a very limited "safe" vocabulary. Since there are only so many ways to explain a scientific process, the probability of your word choice matching an AI's training data is very high.
3. How can I prove I wrote something myself?
Keep your Google Docs version history or Track Changes in Word. This shows the "living" evolution of your thoughts, which no AI-generated "all-at-once" text can replicate.
4. Should I use an "AI humanizer" tool?
If you use one, use it to identify which sentences are too "predictable." Don't let a tool rewrite your soul; use it to see where you need to add more of your own specific, "bursty" human voice.

Related Articles
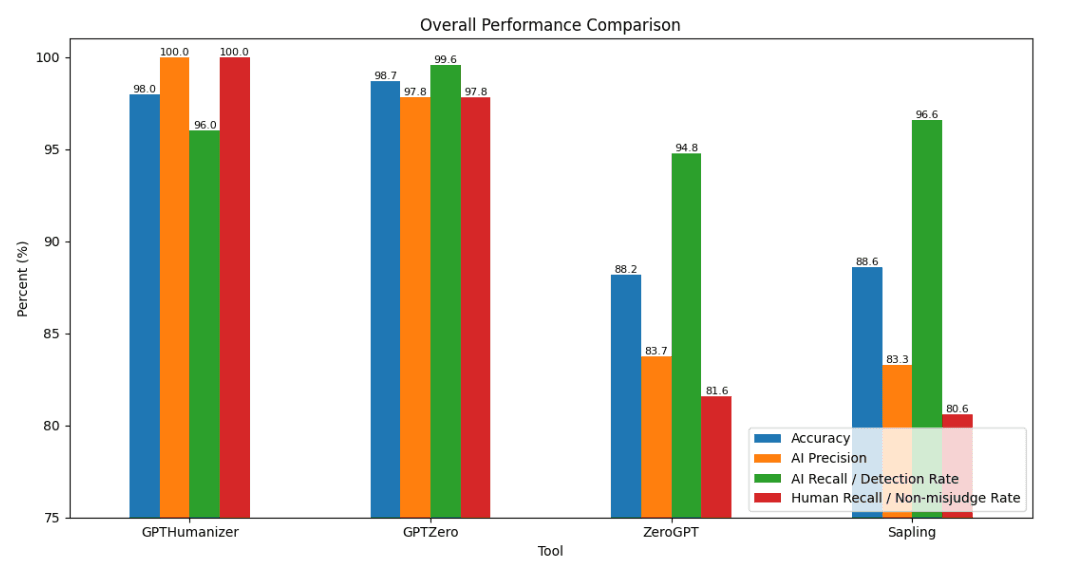
2026 AI Detector Benchmark: Can You Really Trust AI Detectors?
We tested GPTHumanizer, GPTZero, ZeroGPT, and Sapling on 1,000 English texts to compare AI detection...

GPTinf AI Detector Review: Is Its Checker Actually Reliable?
GPTinf AI Detector review with real tests on AI text, human writing, GPTinf output, GPTHumanizer AI ...