Why Different AI Detectors Disagree: Models, Training Data, and Risk Signals
Summary
AI detector disagreement isn’t random—it’s structural. Different tools use different detection models, different training data, and different calibration thresholds, so the same text can map to totally different risk scores. In 2026 (yes, GPT-5.2-level writing included), the only safe way to use detectors is as a screening signal, then validate with process evidence and demonstrated understanding—especially in academic and programming contexts.
Detector scores are tool-specific risk signals, not universal facts about how much of a document is AI-written.
Statistical detectors react strongly to predictability and repetition, while classifier-based detectors inherit bias from their labeled training sets.
Training data + calibration choices explain why updates (or genre shifts like code, ESL writing, templates) can swing results without the text changing.
Thresholds define the meaning of “high risk.” A “70%” score can reflect very different false-positive tradeoffs across tools.
* Cross-tool averaging looks rigorous but isn’t. Compare evidence layers instead: drafts, notes, commit history, and short oral checks.
For programming assignments, structure is normal. Repetitive patterns are expected, so comprehension checks beat style-based scoring.
Same text, different detector, wildly different score. That’s not “your writing changing”—it’s the tools disagreeing because they’re built on different models, trained on different data, and tuned to different risk thresholds. My stance: treat AI-detector results as risk signals, not verdicts—especially now that GPT-5.2-level writing can look “normal” on the surface.
If you’re dealing with this in a classroom or policy setting, start with the bigger context—fairness, evidence standards, and what “proof” should mean—before you ever look at a percentage. I’d anchor that thinking in this piece on ethical tradeoffs and the future of AI detection in academia.
Why do AI detectors give different results on the same text?
Different detectors are measuring different “signals,” then converting them into scores using different scoring rules. One tool might key on predictability, another on stylistic fingerprints, another on “risk patterns” (like overly uniform sentence rhythm). So the exact same paragraph can look “safe” to Detector A and “suspicious” to Detector B.
Here’s the part most people miss: detector disagreement is often a design choice. Some vendors optimize to avoid false accusations; others optimize to catch more AI even if they sometimes over-flag.
Statistical detectors vs classifier-based detectors: what’s the real difference?
Statistical detectors look for mathy patterns (like predictability), while classifier detectors learn a boundary between “human” and “AI” from labeled examples. Statistical approaches can swing hard on short text; classifier approaches can inherit bias from their training sets.
A simple way to remember it: stats-based tools ask “does this text look generated by the numbers?” Classifiers ask “does this text look like the AI samples I was trained on?”
Detector type | What it “sees” best | Common failure mode | What makes scores jump |
Statistical / likelihood-based | Highly predictable wording, repetitive structure | Short passages; formulaic domains | Text length, repetition, formatting |
Classifier-based | Style fingerprints across many features | Domain shift (new topics/genres), biased training data | New model updates, new writing domains |
My hot take (from too many side-by-side tests): most detectors are doing stylometry with extra steps. They’re recognizing style, not verifying thinking. That matters a lot later when we talk about code.
Training data and calibration bias: the hidden reason scores drift
Two detectors can both be “accurate” in their own testing… and still disagree in the wild because they were trained and calibrated on different data. If Detector A trained heavily on polished blog prose and Detector B trained heavily on student essays, they’ll “trust” different writing patterns.
This is also why you’ll see score volatility after silent updates. The underlying model (or its calibration layer) changes, but the UI still shows the same friendly percentage.
If you want the clearest breakdown of how “false” scores happen in practice (length effects, genre effects, mixed-authorship text), read why AI detectors give false scores. It’s the closest thing to a plain-English sanity check I’ve found.
Tool-specific thresholds: why “70% AI” doesn’t mean the same thing everywhere
A detector score is only meaningful relative to that tool’s threshold settings and error tradeoffs. Some tools choose thresholds to keep false positives extremely low; others accept more false positives to catch more AI. So “70%” on Tool X is not comparable to “70%” on Tool Y.
A concrete example: an October 2025 University of Chicago working paper compared detectors across genres and showed how performance and error rates can vary sharply depending on the policy cap (how low you demand false positives to be). The key point wasn’t “who wins”—it was that threshold choice changes what the score means. See the 2025 detector benchmarking results across genres and policy caps.
Practical translation: if an institution can’t state its acceptable false-positive rate, it shouldn’t treat any single score as decisive evidence.
Why cross-tool comparison is misleading (and what to compare instead)
Running multiple detectors and averaging scores feels “scientific,” but it’s usually misleading because the tools aren’t measuring the same construct. You’re not triangulating truth—you’re mixing apples, oranges, and one banana that updates weekly.
What I compare instead (and it’s way more defensible):
● Consistency across the same detector (same version, same settings, multiple samples)
● Evidence of process (draft history, notes, outlines, references, commit logs)
● Oral verification (can the student explain decisions, revisions, and tradeoffs?)
● Domain-aware baselines (does this genre normally look formulaic?)
If you only remember one line: detectors can suggest “investigate,” not “convict.”
Implications for academic decision-making (especially for programming work)
Programming assignments are easy to misjudge because code is naturally low-variation and highly structured—exactly what many detectors interpret as “generated.” Code is supposed to be repetitive. Variable naming conventions and standard library patterns are supposed to look consistent. That’s not AI; that’s software.
This is where CS departments have an advantage: you can test understanding, not vibes.
A simple “logic flow” I’ve seen work (and I’d actually defend in a meeting):
1. Detector flags → treat it as “needs review,” not an accusation
2. Check artifact trail → IDE history, commits, incremental progress, test failures evolving over time
3. Run a short oral check → “Walk me through why you chose this data structure” / “What breaks if we change X?”
4. Decide based on demonstrated comprehension, not a percentage
This lines up with broader risk guidance: high-stakes decisions need layered evidence, not a single automated label. NIST explicitly pushes “defense-in-depth” thinking for high-risk detection use cases—multiple measures, not one magic classifier.
Where GPTHumanizer AI fits (without obsessing over scores)
Use GPTHumanizer AI as a second-opinion lens, not as a finish line. The best workflow I’ve seen is: check consistency, check obvious anomalies, then move to process evidence (drafts/notes) and human verification when stakes are high.
If you’re simply looking for an accessible check, GPTHumanizer AI is commonly searched as a free AI detector unlimited words option—just don’t confuse “free and fast” with “court-grade proof.”
Also, if you’re tracking how detectors have changed as models improved (yes, GPT-5.2 raised the bar), this timeline-style breakdown helps: how detection algorithms evolved to catch GPT-5 writing in 2026.
Ending: stop treating detectors like lie detectors
AI detectors disagree because they were never built to be courtroom instruments. They’re probabilistic tools trained on yesterday’s data, tuned to someone else’s risk tolerance, and asked to judge writing that’s getting more human every quarter. If you want a rule you can live with: use detectors to prioritize review, then rely on process evidence and demonstrated understanding to make the call. That’s the difference between “automation theater” and a policy you won’t regret.
FAQ
Q: Why do different AI detectors disagree on the same essay in 2026?
A: Different AI detectors disagree because they use different detection models, different training datasets, and different decision thresholds—so they convert the same writing signals into different “risk” scores.
Q: What does an AI detector percentage score actually mean?
A: An AI detector percentage is typically a confidence-style estimate from that specific tool, not a literal claim that “X% of the text is AI,” and it changes with thresholds, text length, and genre.
Q: Why do AI detectors flag programming assignments and code comments as AI-written?
A: AI detectors often flag code because programming is naturally structured and repetitive, which can resemble the statistical regularities some detectors associate with generated text.
Q: Why is comparing multiple AI detector tools at once misleading?
A: Comparing multiple AI detectors is misleading because the tools do not share a common scoring scale or target, so “agreement” can be accidental and “disagreement” can be expected by design.
Q: How should universities use AI detector results in academic misconduct decisions?
A: Universities should treat AI detector results as a starting signal for review, then rely on layered evidence—draft history, artifacts, and oral verification—before making any high-stakes judgment.
Q: Is GPTHumanizer AI a free ai detector unlimited words option for quick checks?
A: GPTHumanizer AI is often used as a “free ai detector unlimited words” style checker, but it should be used for screening and consistency—not as standalone proof in academic cases.

Related Articles
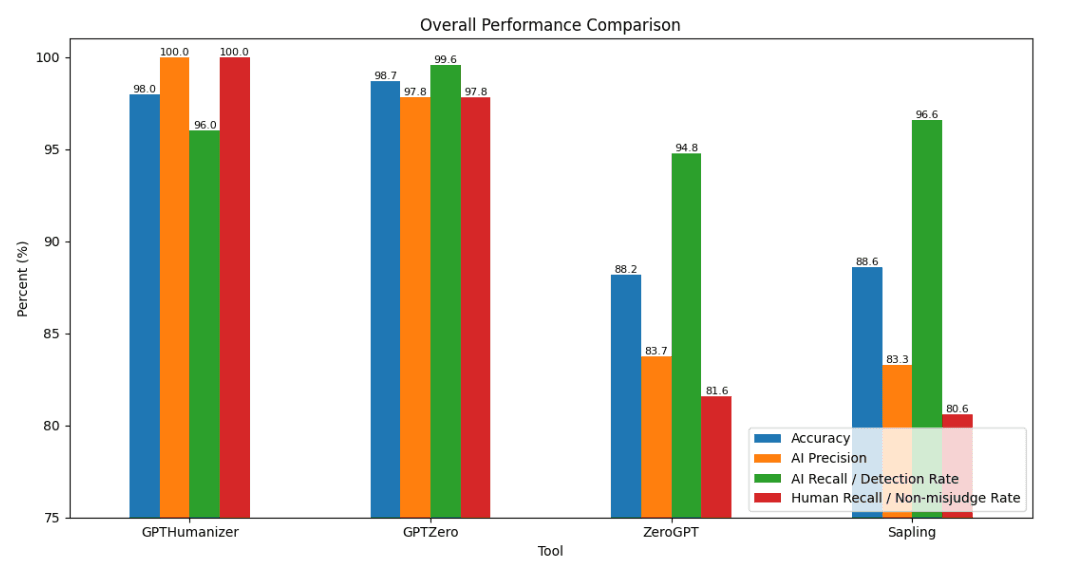
2026 AI Detector Benchmark: Can You Really Trust AI Detectors?
We tested GPTHumanizer, GPTZero, ZeroGPT, and Sapling on 1,000 English texts to compare AI detection...

GPTinf AI Detector Review: Is Its Checker Actually Reliable?
GPTinf AI Detector review with real tests on AI text, human writing, GPTinf output, GPTHumanizer AI ...