Perplexity and Burstiness Explained: What AI Detectors Measure — and What They Don’t (2026)
Almost every serious AI detection conversation has become almost exclusively about two technical buzzwords these last few years: perplexity and burstiness.
As we explore in-depth elsewhere, in “The Technical Evolution of AI Humanizers from Paraphrasing to Neural Editing” ,many misconceptions about these metrics stem from outdated ideas inherited from early paraphrasing tools, rather than modern neural editing perspectives.
I keep hearing them mentioned in product pages, on Reddit, funny YouTubers’ breakdown videos, and my own weak-advice-as-usual, “Just mix up your sentences, the AI score will fall.” The idea sounds so obvious. AI-generated text is almost always smooth, even, safe. If you just make it more “messy,” it should become more human.
In reality, this way of thinking silently does way more damage than most of us realize.
This isn’t an article for “shutting down” perplexity and burstiness. They’re useful, legitimate statistical signals. What I am trying to do here is return them to their proper place as tools for understanding patterns, not goals to optimize towards. As you mix up the two, the quality of your writing subtly, but surely, begins to suffer.

1. Why Perplexity and Burstiness Became So Confusing
This is stuff that most people don’t see in linguistics/NLP research; it’s things that they see in AI detection tools like GPTZero, where perplexity and burstiness are reduced to “AI-likeness” metrics.
There’s a logical place that stems from that framing: if detectors penalize low perplexity and low burstiness, then if you “increase them”, your text will be safer. The issue is that we’ve turned what are descriptive metrics into prescriptive variables.
Perplexity and burstiness are tendencies that tend to surface in certain kinds of generated text. They have nothing to do with intent or authorship, or editorial quality. Rewrites that interpret them as levers to pull rather than signals to watch are where good intentions go wrong.
2. What Perplexity Is Really Measuring
At a glance, perplexity is just a probability measure. It measures how predictable a sequence is to a language model. Whenever the next word is really predicted, perplexity is low. Whenever the model is surprised, perplexity high.
This is why many first AI drafts often have very low perplexity. They know the common phrases, optical transitions, balanced clauses. None of it is bad. Many kinds of professional communications, academic papers, technical documentation, legalese, are designed to be predictable.
The thing I had to learn to separate is this: predictability is not the same as artificiality. Low perplexity does not equal “machine-written,” and high perplexity does not equal “human-written.” It is just as much about how statistically expected the wording it a model’s training distribution.
You can push perplexity high very slightly by making text more unusual, longer, and less specific. That does not improve it. It makes it harder to predict.
3. Burstiness Is Rhythm, Not Noise
Regular bursts of ideas alternate naturally between pretty dense explanation and short emphasis, between long sentences that head on to the next thought and short ones that hit the reader in the nose.
AI-generated drafts fall into regular cadence. The sentences are good, but they arrive in a regular rhythm that becomes slightly mechanical, when you notice.
The mistake people make is assuming that burstiness needs to be made. I have read many so-called “humanized” passages that alternated sentence length or inserted fragments just to create contrast. The result is rarely true to life. It is more akin to an imitation. Emphasis is misplaced. It feels forced. It feels less natural.
The correct reasoning is that burstiness follows meaning. Your ideas are regular, meaning that the words that express them need not be. Language breaks down when you do this.
4. How AI Detectors Use These Signals
AI detectors are not single numbers. Perplexity and burstiness are just usually paired with a whole lot of other statistical signals: probability distributions, repetition patterns, model-specific likelihood features.
DetectGPT, and other methods, make this clear by not trying to decide whether text is “good” or “bad” but looking for probability patterns that match known generation patterns and flagging them for human review.
That’s why detectors are risk indicators, not verdicts – Turnitin even calls AI detection an assistive signal to aid human judgment, not replace it.
Once you can see detectors that way, the impulse to “optimise” directly for that signal starts to feel a bit off.
Once these signals are misunderstood as goals rather than diagnostics, the damage becomes subtle but systemic.
That’s why detectors are risk indicators, not verdicts — Turnitin itself explicitly frames AI detection as an assistive signal meant to support human judgment, not replace it.
At a glance, perplexity is just a probability measure — in NLP terms, it describes how predictable a word sequence is to a language model, not whether it is “human” or “artificial.”
5. When metric chasing ruins writing
The most destructive kinds of metric-chasing humanization are usually invisible. They rarely shatter the text in a dramatic fashion, shattering grammar or coherence. Instead, they creep in and undercut the writing.
In some drafts I’ve read, the price of lowering the AI score was blandness. They lost numbers. Dates. Powerful causal statements were squeaked into weakly associative ones. Document structure was flattened for lack of variety.
I’ve seen drafts where lowering the AI score meant deleting dates, softening causal claims, or replacing concrete numbers with vague qualifiers — changes that made the text safer statistically, but weaker editorially.
None of these are usually flags that light up perplexity charts. But any reasonable reader will see them. The text may be “safer” for a detector, even if it feels less solid, less precise, harder to defend.
That’s why I stopped treating detection metrics as objectives. They are useful when you try to figure out why a text feels weird. They are destructive as objectives.
6. Editing for Readers Rather Than for Scores
The best way I can get a sense of how natural a draft reads is to not even think of perplexity and burstiness.
Instead, I think of the draft as if I were a copy editor. Does each sentence belong there? Are my transitions actually doing logical work? Is the rhythm of my sentences coming from the ideas instead of my perplexity score? Would I be comfortable putting my name on this version to submit or publish?
When you edit with those questions in mind, a predictable thing happens. Repetition goes down. Sentence rhythm varies more. Predictability decreases, but in a nice way that is still clear and accurate. The numbers change as a corollary of good writing, not as the focus of good writing.
7. Where Perplexity and Burstiness Rightfully Belong
In a professional setting, perplexity and burstiness live in the analysis phase. They tell you why something is the way it is. They don’t tell you how you should write or edit that draft.
When variation is too low, that’s a red flag. When rhythm feels like a jig, that is also useful. But you can’t tell me if your writing is accurate, responsible, or publishable with just those two metrics. You need a broader set of criteria: fidelity to meaning, integrity of information, structural soundness, reader trust.
Metrics characterize the text, not the editors.
8. Conclusion
Perplexity and burstiness are lenses, not compasses.
They can tell you why some writing feels like a laugh, especially at scale. They can’t tell you how you should make writing better, more credible, worth signing. Treat them as optimization targets and they incentivize empty fixes that secretly dilute meaning and precision.
The most reliable approach I’ve found isn’t the most exciting: edit for clarity, accuracy, and structure first. Let the statistical signals come naturally. When humanization is done this way, the writing improves, and the numbers do, too, often without being pursued.
If there’s one thing worth remembering in 2026, it’s this: no detector metric can tell you whether a piece of writing is accurate, responsible, or worth attaching your name to.
That is the standard I’m comfortable standing behind in 2026:
humanize for readers, not for metrics.
FAQ: Perplexity, Burstiness & AI Detection
1. What exactly are perplexity and burstiness in AI detection?
“Perplexity” measures how predictable text is based on a language model’s probabilities. Lower perplexity usually means the model can easily predict the next word, which AI tends to do; human text is often less predictable. “Burstiness” measures variation in sentence length and structure — humans tend to vary more than typical AI outputs.
2. Why do most AI detectors use these metrics?
Many detectors (including GPTZero and similar tools) use perplexity and burstiness to spot linguistic patterns that often correlate with AI writing versus human writing. However, detectors pair them with other features and statistical signals.
3. Are these metrics reliable? Can we trust detection results?
No detector is perfect. Tools can be somewhat accurate, but performance varies widely by text length, style, and writing quality. Detectors often give a probability or likelihood score, not a definitive answer.
4. Can human-written text ever be wrongly flagged as AI?
Yes — human writing sometimes gets mistakenly classified as AI-generated, especially if it’s very uniform, formal, or predictable. This is a known limitation and a frequent complaint online.
5. Do AI detectors work equally well for all languages?
Many detectors are mainly trained on English and can struggle with non-English text or multilingual content. Their reliability in other languages may be lower.
6. Can slight edits or paraphrasing change a detector’s result?
Yes — even simple changes, paraphrasing, or editing an AI-generated draft often significantly drops the likelihood that a detector tags it as AI-written.
7. Are detectors biased against certain writers (e.g., ESL writers)?
Research and reports suggest detectors can flag text from non-native English speakers more often, because their writing may have patterns (e.g., vocabulary or sentence style) that resemble low perplexity or burstiness.
8. If detectors aren’t perfect, why do people keep using them?
Detectors are often used as risk indicators or supplementary tools — for educators, editors, and institutions who want signals about possible AI-generated writing, not final judgments.
9. Do detectors measure “quality” or just AI-likeness?
Most detectors focus on statistical patterns — not writing quality, accuracy, or credibility. Some people misunderstand scores as quality metrics, but that’s not their purpose.
10. With constantly improving AI, will detectors keep up?
It’s a known challenge. As language models get more advanced, their output often looks more human, while detectors must constantly update to new linguistic patterns. This is an ongoing “arms race.”

Related Articles
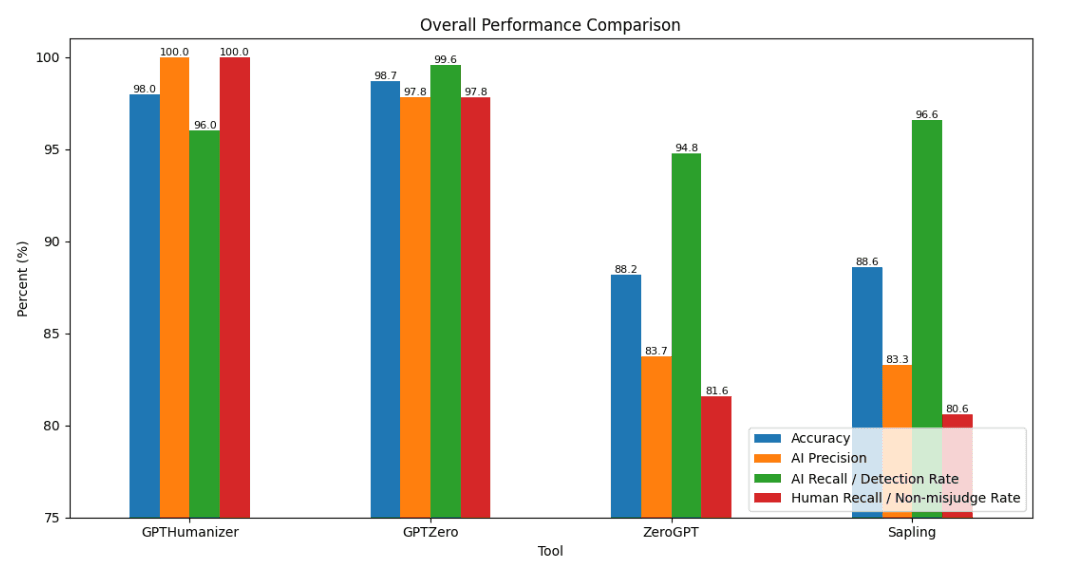
2026 AI Detector Benchmark: Can You Really Trust AI Detectors?
We tested GPTHumanizer, GPTZero, ZeroGPT, and Sapling on 1,000 English texts to compare AI detection...

GPTinf AI Detector Review: Is Its Checker Actually Reliable?
GPTinf AI Detector review with real tests on AI text, human writing, GPTinf output, GPTHumanizer AI ...