The Professor's Dilemma: How Educators are Adapting to AI Writing in 2026
Summary
Reasoning
* Fairness and Reliability: Detection signals are not definitive and can raise fairness issues; the stronger approach is verifying process and understanding.
* The Proof-of-Learning Triad: The most durable model combines (1) process evidence checkpoints, (2) short oral/live verification for high-stakes work, and (3) clear disclosure rules for responsible AI use.
Conclusion
In 2026, educators aren’t “beating” AI writing—they’re changing what counts as proof of learning. The best professors I work with treat AI detectors as a conversation starter, then validate authorship through writing process, targeted checkpoints, and assessment redesign that rewards original thinking (even when students use ChatGPT GPT-5.2).
What educators are actually dealing with in 2026
The reality is simple: AI writing is now a default tool, not an edge case. Students use it to brainstorm, outline, translate, and polish. Some also use it to outsource the whole assignment.
What changed isn’t just the tools—it’s the “normal.” Even strong students sound more uniform because AI nudges them toward the same tidy structure and safe phrasing.
If you want the deeper ethics + policy context (and the messy edge cases faculty keep running into), this breakdown on academic AI detection challenges and where the ethics debate is heading is worth having in your back pocket.
My stance: AI detectors measure style, not truth
AI detection is mainly pattern matching on writing style, not a reliable test of who did the thinking. That’s why “AI score” arguments blow up: faculty are using a style signal to make an authorship claim.
And the fairness risks are real. Research from Stanford-affiliated authors (including James Zou) shows many detectors can disproportionately flag non-native English writing as “AI,” which is a nightmare scenario if your process is “detector score → penalty.” Here’s the paper: GPT detectors are biased against non-native English writers.
So yes, detection can be useful. But only if you treat it the way you treat a smoke alarm: it tells you to look closer, not to declare guilt.
What works better than “gotcha” enforcement
The most effective shift I’m seeing is moving from policing outputs to verifying process. That means the assignment is designed so a student can’t succeed without demonstrating their thinking steps.
Here are the three moves that consistently reduce conflict and improve learning outcomes:
Build “process evidence” into the grade
If you grade the path, not just the final draft, AI becomes easier to discuss and harder to abuse. Practical options:
Outline + thesis checkpoint (graded lightly, fast feedback)
Annotated sources (why this source, what it changes)
Revision memo (“what I changed and why”)
Version history or drafting screenshots (when appropriate)
Downside? It adds grading touchpoints. Upside? You get fewer integrity disputes, and students learn more.
Use short oral or live checks for high-stakes work
A 5–7 minute oral check can outperform any detector for confirming understanding. Not an interrogation—more like: “Walk me through your argument. Why this evidence? What would you change if X were true?”
The first time I suggested this to a faculty team, they hated it. Then they tried it with just their top-risk assignments and saw the tradeoff: fewer long investigations, more clarity, better student accountability.
Make AI use discussable, not taboo
Clear disclosure rules reduce cheating more than vague threats. If students don’t know what’s allowed, they hide everything—including legitimate help like language polishing.
A simple policy that works surprisingly well:
Allowed: brainstorming, outlining, editing for clarity
Required: a short “AI use note” when used
Not allowed: generating the full submission as-is
Not perfect, but it creates a norm you can actually enforce.
Comparison table: detector-first vs proof-of-learning design
If you need fewer disputes and better learning, “proof-of-learning” beats “detector-first” most of the time.
Approach | What it’s really measuring | Strength | Weak spot | Best use case |
Detector-first enforcement | Style probability | Fast triage | False positives + fairness risk | Early signal to trigger a review |
Proof-of-learning design | Thinking process + authorship evidence | Strong defensibility | More instructor effort | High-stakes writing, capstones |
Oral/live verification | Student understanding | High confidence | Scheduling | Small classes, key assignments |
Transparent AI policy | Norm-setting | Reduces hiding | Requires consistency | Any course using writing |
A practical decision flow when a paper looks “too AI”
A clean workflow lowers stress for you and students because it replaces vibes with steps. Here’s the flow I recommend when you suspect overreliance on AI writing:
Flowchart (text version):
→ 1) Flag: unusual uniformity, sudden style shift, or detector signal (optional)
→ 2) Request process evidence: outline, sources notes, revision memo, version history
→ 3) Short interview (5–7 minutes): explain claim → defend evidence → revise counterpoint
→ 4) Outcome:
If understanding is clear → coaching + policy reminder
If gaps are major → redo assignment with scaffolding
If deception is evident + policy supports it → formal integrity process
This protects students who write differently (or imperfectly) while still holding the line on actual outsourcing.
Where UNESCO and faculty development teams are landing
The “grown-up” position is: keep humans in charge, and design learning around human agency. UNESCO’s guidance pushes a human-centered approach—policy, capacity-building, and responsible use—rather than pretending GenAI doesn’t exist. If you need a reputable reference point for institutional conversations, use UNESCO’s guidance for generative AI in education and research.
Also, if your department needs practical examples of assessment redesign (not theory), this workshop-style video is a solid internal training share: Generative AI in Higher Education: A Deep Dive into Assessment Redesign.
Where GPTHumanizer AI fits (and where it doesn’t)
Used responsibly, an AI detector like GPTHumanizer AI can help start the right conversation—but it should never be the verdict. In practice, it’s most useful for:
Spotting sudden shifts in tone across sections
Prioritizing which submissions deserve a closer look
Supporting coaching conversations (“Let’s review your draft process”)
What it can’t do is prove intent. And it definitely can’t replace assessment design.
If you want one hard number to keep expectations sane, Turnitin has publicly discussed false positive rates and how sentence-level highlighting can be noisier than document-level signals: Turnitin’s explanation of false positive rates in AI writing detection.
Ending the “professor’s dilemma” without lowering standards
The dilemma isn’t “AI or no AI.” It’s this: Do we grade polish, or do we grade thinking? In 2026, polishing is cheap. Thinking is still the scarce asset.
My recommendation is opinionated on purpose: stop trying to win a detection arms race. Put your effort into proof-of-learning design—process evidence, targeted checkpoints, and short verification moments for high-stakes work. You’ll get fewer false accusations, fewer outsourced papers, and better student growth.
So, is it more work upfront? Yes. But it’s also the first approach I’ve seen that scales without turning every assignment into a courtroom.
FAQ (People Also Ask)
Q: How accurate are AI writing detectors for university assignments in 2026?
A: AI writing detectors are best treated as probabilistic style signals, not proof of authorship, because false positives and uneven performance across writing styles still occur and require human verification.
Q: What is the safest university policy for student use of ChatGPT GPT-5.2 in writing assignments?
A: A “disclose-and-explain” policy is safest, allowing limited AI help (brainstorming/editing) while requiring a short usage note and grading process evidence, not just the final draft.
Q: Can AI writing detectors unfairly flag non-native English students as AI-generated?
A: Yes, multiple studies show detectors can disproportionately flag non-native English writing, so any enforcement process must include process evidence and student explanation before penalties.
Q: What assessment types are most resistant to AI-written submissions without banning AI?
A: Assessments that require personal context, iterative checkpoints, and live explanation are most resistant, because they demand evidence of thinking, not just polished text.
Q: How should educators respond when an AI detector score is high but the student denies AI use?
A: Ask for process evidence first (outline, sources notes, revision memo, version history), then do a short oral explanation check, because that establishes understanding without relying on a single tool score.
Q: Does the GPTHumanizer AI detector actually help educators manage AI writing concerns?
A: GPTHumanizer AI is most helpful as a triage signal and conversation starter, but it should be paired with assessment design and authorship verification steps to avoid overreach.
Q: What is the best way to prove student authorship for writing assignments in 2026?
A: The best proof is a combination of process artifacts (draft checkpoints) and a brief oral defense, because it demonstrates both creation history and real understanding.

Related Articles
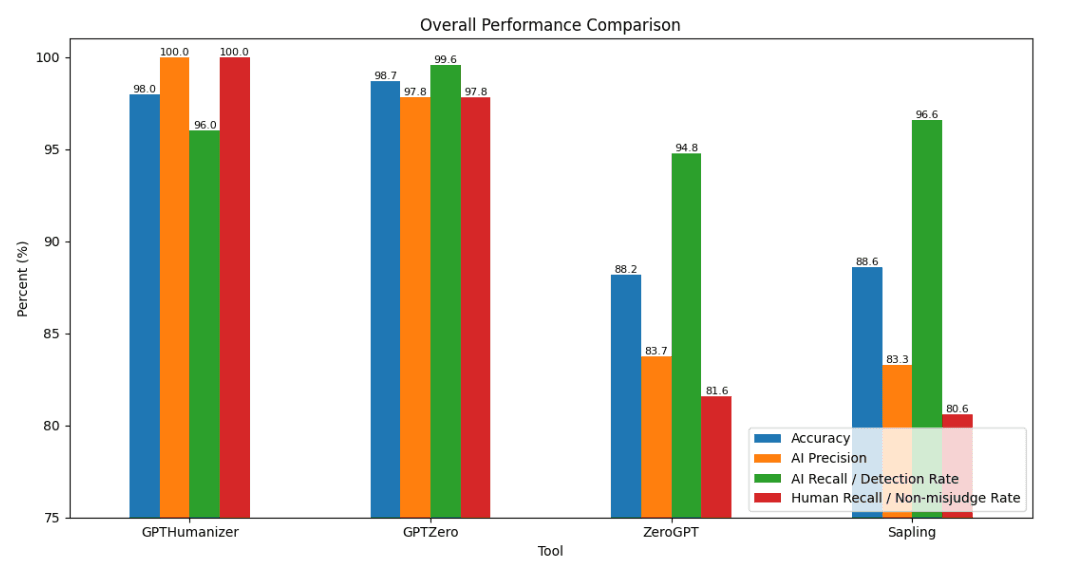
2026 AI Detector Benchmark: Can You Really Trust AI Detectors?
We tested GPTHumanizer, GPTZero, ZeroGPT, and Sapling on 1,000 English texts to compare AI detection...

GPTinf AI Detector Review: Is Its Checker Actually Reliable?
GPTinf AI Detector review with real tests on AI text, human writing, GPTinf output, GPTHumanizer AI ...