Stress Testing GPTHumanizer AI: How to Judge Rewrite Stability on Real Drafts
Summary
This article explains how to judge GPTHumanizer AI more realistically by looking at rewrite stability instead of surface-level change. It shows why rewrite depth, style control, and built-in detector feedback matter in different ways, and why stronger output still depends on section-by-section review when the content is fact-sensitive or structurally important.
The main takeaway is that GPTHumanizer AI becomes more valuable as the draft becomes harder, but only if it is evaluated the right way. The strongest test is not whether the wording changes, but whether the rewrite stays natural without weakening meaning, structure, or editorial intent.
Most humanizers will seem reasonable when you test them on the simple clean paragraph. A short intro with no numbers to parse, no snootsy technical jargons, no structural craziness can make almost every tool look decent. It is only when the draft gets difficult to rewrite where you get the real picture, be it a long run-on with repeated concepts, a comparison page with identical product information, a section with technical language, or a mixed-draft which jumps from headings and bullets to FAQs to short text blocks.
This is why I find it more interesting to compare the GPTHumanizer AI on difficult drafts than on polished demos. If you already read my pillar article onthe technical evolution of AI humanizers from paraphrasing to neural editing, then this article is a practical extension of that. The question is not merely whether contemporary humanizers can rewrite deeper than synonym replacers, but whether that deep rewriting can still be kept under control when the input is too long, factual, technical or structurally complex.
What robustness means in AI humanization
Robustness in AI humanization is the question of whether a system can still positively affect readability and naturalness when the draft is harder to manage. A quick paragraph doesn't say much. The proper test is whether the rewrite still withstands long form continuity, exact claims, technical vocab, structural formatting, and tone sensitive sections where smoothening too much can attenuate intent.
This is important since a superficial improvement is not equal to solid editing. A limp humanizer will prettify the text but quietly smooth facts, tone, structure. A robust system can improve flow while retaining the bits that still need to be precise. This is why robustness is important in the GPTHumanizer AI evaluation test suite for the important task of making a difficult draft read more natural without losing meaning or structure.
Why GPTHumanizer AI should be judged differently from a shallow rewriter
Many AI humanizer articles are soundly interchangeable because they describe the category in a way that could describe almost any tool. That is not particularly helpful here. GPTHumanizer AI is not useful because it only changes a few words and makes the paragraph appear different. Its real usefulness is in reworking the sentence flow, decreasing the AI guessable phrasing, and making the text more readable without diminishing meaning or structure.
That difference is evident when you consider how the product is actually used. GPTHumanizer AI offers different depths of rewrite in its Lite, Pro, and Ultra levels, which is important because not every section should be edited with the same intensity. A shaggy fact paragraph, a technical explanation, and a flat but repetitive introduction do not need the same kind of attention. When a tool forces every section through the same rewrite recipe, the result is either too light to be helpful or too heavy to be trustworthy.
The same applies to style control. When you have a weaker tool, style controls often sound trivial. In practice, style changes the way a section behaves on the page. It changes the directness, warmth, and overall movement of the paragraph, which is significant because a founder note, a comparison section, and a technical explainer should not all sound the same.
The built-in detector, too, feels more like a part of the review process rather than a finish line. I would not consider it a definitive beacon that the content is ready. I would consider it a secondary signal that helps you tell if the output still feels too even or too mechanically written. That is why GPTHumanizer AI is more useful when evaluated as an editing system rather than merely a surface-level rewrite.
Where GPTHumanizer AI should be tested hardest
The simplest way to unfairly overestimate any humanizer is to evaluate it only on paragraphs where the humanizer has little hope of failing. The more interesting test is to give it more value but also risk, areas where the stronger rewrite is most valuable.
Long-form is a good place to look, because continuity across sections, not copy, contributes to the value of a long writeup and a humanizer has to work across sections, not just paragraph. A humanizer can make a paragraph flow more beautifully quietly erasing the subtle gradations of emphasis and transition between sections. All the ideas on the last page might just seem a smidge more closely related after a rewrite and the structure might be unintentionally erased. A humanizer gives the word-wrangler with more depth of rewrite a chance to cut redundancy and improve flow but it still may not have another rewrite of the section.
Heavily fact-pars are another interesting test. If a section or paragraph is packed with feature counts, plan names, pricing logic, dates and product distinction, it can be improved as words but not as facts. A sentence more natural sounding is no better if it dilutes the meaning of the claim. So rewrite depth needs to be tailored to places where the message needs to be precise.
Technical sections are a similar test. The humanizer may try to make a technical section easier to read but it doesn't know which phrases to preserve and which are extra. In a technical section the goal is not to simplify everything but to make it read more smoothly and keep the meaning.
Similar tests are available elsewhere. FAQs, bullets, comparison blocks, short summary section and the like all need to stay easy to scan. A humanizer can rewrite each sentence and make the page harder to read by drowning in texture or padding the short sections without meaning. We need to see if GPTHumanizer AI can get these sections a bit more natural sounding without drowning the useful editorial structure.
A practical validation on a fact-sensitive product paragraph
Up to this point, the article has focused on where AI humanization usually becomes less reliable: continuity across long sections, exact claims, technical terminology, and structured content that still needs to stay usable. A practical product-focused test helps make that discussion more concrete.
This example does not cover every edge case in the article, and it is not meant to function as a full robustness benchmark. What it does show is something more specific and still very useful: whether GPTHumanizer AI can rewrite a fact-sensitive product paragraph without weakening the exact details inside it.
In this case, the source paragraph included several points that should remain stable after rewriting: the role of Lite, Pro, and Ultra, the importance of rewrite depth, support for 11 languages, 8 writing styles, a built-in detector, and the free Lite model’s 300-word limit per request without sign-up. Those details match the current feature framing shown on GPTHumanizer’s official pages.
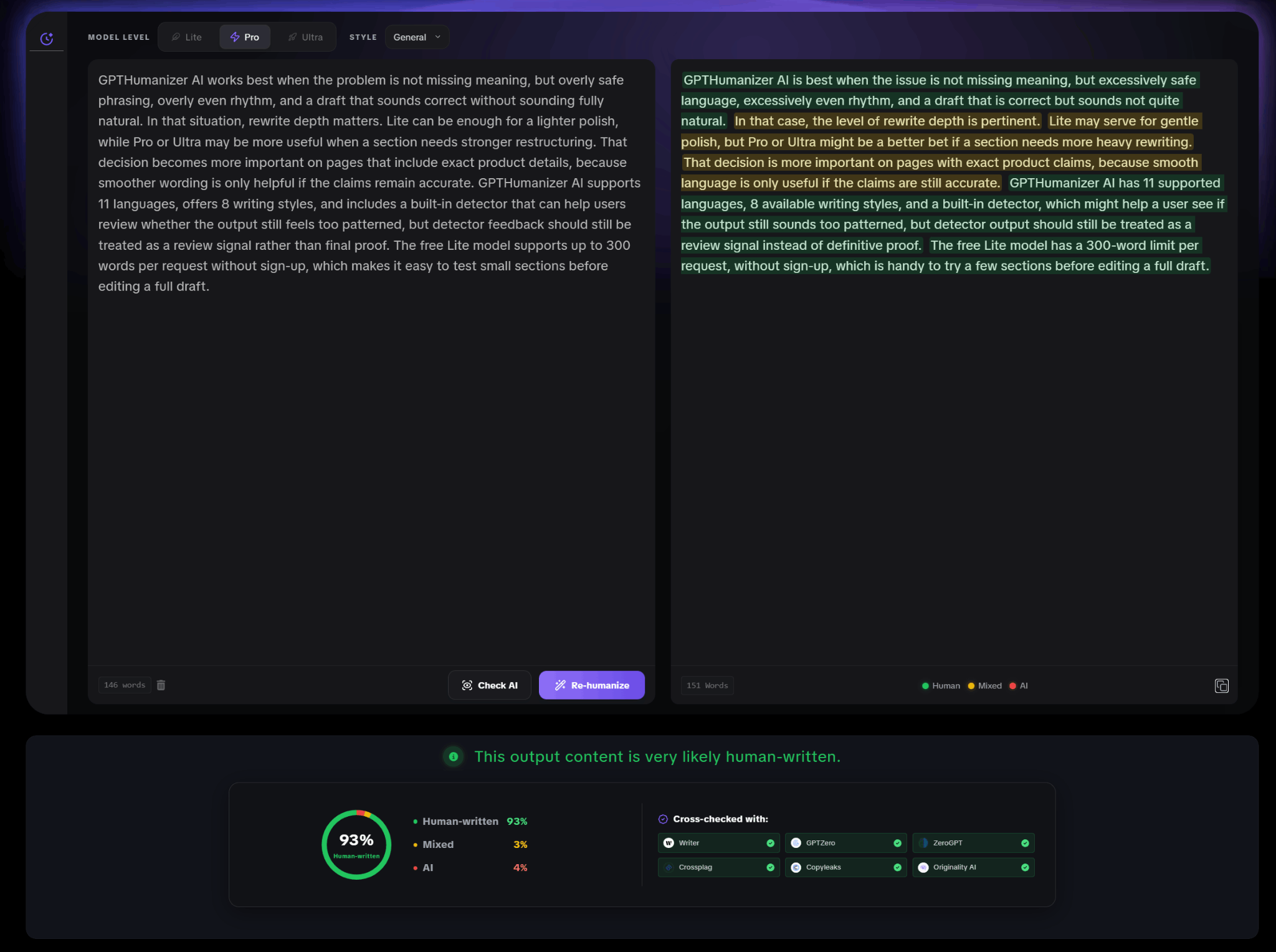
Original draft
GPTHumanizer AI works best when the problem is not missing meaning, but overly safe phrasing, overly even rhythm, and a draft that sounds correct without sounding fully natural. In that situation, rewrite depth matters. Lite can be enough for a lighter polish, while Pro or Ultra may be more useful when a section needs stronger restructuring. That decision becomes more important on pages that include exact product details, because smoother wording is only helpful if the claims remain accurate. GPTHumanizer AI supports 11 languages, offers 8 writing styles, and includes a built-in detector that can help users review whether the output still feels too patterned, but detector feedback should still be treated as a review signal rather than final proof. The free Lite model supports up to 300 words per request without sign-up, which makes it easy to test small sections before editing a full draft.
GPTHumanizer AI output (Pro model)
GPTHumanizer AI is best when the issue is not missing meaning, but excessively safe language, excessively even rhythm, and a draft that is correct but sounds not quite natural. In that case, the level of rewrite depth is pertinent. Lite may serve for gentle polish, but Pro or Ultra might be a better bet if a section needs more heavy rewriting. That decision is more important on pages with exact product claims, because smooth language is only useful if the claims are still accurate. GPTHumanizer AI has 11 supported languages, 8 available writing styles, and a built-in detector, which might help a user see if the output still sounds too patterned, but detector output should still be treated as a review signal instead of definitive proof. The free Lite model has a 300-word limit per request, without sign-up, which is handy to try a few sections before editing a full draft.
This example is useful because the rewrite preserved the core product logic and did not erase the exact details that mattered. The distinctions between Lite, Pro, and Ultra remained intact, the language and style counts stayed accurate, and the detector was still framed as a review aid rather than a final guarantee. That is the kind of stability I would want to see in a fact-sensitive product paragraph.
At the same time, the output also shows why final review still matters. A few phrases became more formal or less natural than they needed to be, especially where the rewrite tried to sound more forceful but ended up slightly stiff. In other words, the paragraph remained controlled in meaning, but not every local phrasing choice improved equally. That makes this a realistic validation rather than a polished marketing example.
In the built-in detector panel shown during this test, the rewritten output was labeled as very likely human-written, with a 93% human-written score. I would treat that as a supporting signal rather than proof on its own. The stronger takeaway is that GPTHumanizer AI preserved key product claims while still pushing the paragraph away from flat, overly safe wording, even if the final version would still benefit from light human editing.
What GPTHumanizer AI still should not automate on its own
Any honest article on this topic should be clear about the boundary. GPTHumanizer AI can make AI-generated writing sound less formulaic, less predictable, and more natural to read. It is especially useful when the source draft already contains real ideas but still feels too flat, too uniform, or too mechanically phrased.
What it should not replace is human judgment on high-sensitivity content. Exact data, citations, legal or reputationally sensitive wording, and technical explanations where one softened distinction changes the meaning still deserve deliberate review. This is not a weakness unique to GPTHumanizer AI. It is simply the practical limit of using advanced rewriting responsibly.
In fact, stronger rewriting tools create a different kind of risk. Once the output becomes smoother and more convincing, it becomes easier to trust it too quickly. In real editorial workflows, that overtrust is often more dangerous than obviously weak output because it hides the places where precision still matters most.
Bottom line
The best way to judge GPTHumanizer AI is not to ask whether it can polish a clean paragraph. The more useful question is whether it can keep meaning, structure, and tone stable when the draft is long, technical, fact-sensitive, or structurally mixed. That is where rewrite stability stops being an abstract technical idea and starts becoming an editorial requirement.
Viewed that way, GPTHumanizer AI stands out less because it can rewrite text and more because it gives you a more controllable form of rewriting. Lite, Pro, and Ultra are not just model labels in this context. They are part of how you decide how much editorial pressure a section should take. Style control is not just decoration. It affects how the section behaves on the page. The built-in detector is not the final answer. It is part of the review loop. Those product elements are all reflected in GPTHumanizer’s current public positioning.
That combination is what makes the tool worth evaluating more seriously than a surface-level paraphraser. It does not remove the need for review, especially where factual precision matters, but it does make GPTHumanizer AI more useful in real publishing workflows where naturalness and control have to exist together.
FAQ
What does robustness mean in AI humanization?
In this context, robustness means whether a system can still produce natural, readable, and meaning-faithful output when the input becomes more difficult. That includes long articles, technical explanations, structured sections, and passages with exact facts that should not drift during rewriting.
Why should GPTHumanizer AI be tested on difficult drafts instead of short demo paragraphs?
Short and simple paragraphs make most rewriting tools look acceptable. A more useful test is whether GPTHumanizer AI stays stable when the draft includes repeated ideas, numbers, technical language, mixed formatting, or tone-sensitive sections. Those are the cases that reveal whether the system is only changing wording on the surface or actually improving the text in a controlled way.
How do Lite, Pro, and Ultra affect rewrite stability?
They affect how much rewrite pressure is applied to the section. A lighter pass may be better for fact-heavy or technical content where precision matters most, while a deeper pass may be more useful for flat, repetitive, or overly uniform drafts that need stronger restructuring. GPTHumanizer currently presents Lite, Pro, and Ultra as distinct model options on its public pages.
Can GPTHumanizer AI preserve numbers, names, and product details?
It can improve the phrasing around those details, but fact-heavy sections still need manual review. Numbers, dates, feature claims, pricing references, and citations should always be checked after rewriting because even a natural-sounding edit can become too vague if the section is highly specific.
Does GPTHumanizer AI work well on long-form content?
Yes, but long-form drafts still need section-by-section review. GPTHumanizer AI is stronger than shallow rewriters when a section needs better rhythm, less repetition, and more natural flow, but long articles should still be checked for transitions, continuity, and internal logic after rewriting.
What role does the built-in AI detector play in this workflow?
The built-in detector is more useful as a review signal than a final judgment. It can help flag output that still feels too patterned or overly uniform, but it should support editorial review rather than replace it. GPTHumanizer’s official materials currently describe a built-in detector as part of the workflow.
Can GPTHumanizer AI fully fix a weak draft?
Not completely. It can improve flow, readability, and natural phrasing, but it cannot replace missing structure, factual discipline, or strong judgment in the original draft. A better rewrite can strengthen a decent draft, but it will not automatically repair weak thinking.

Related Articles

What Makes GPTHumanizer AI Trustworthy? Privacy, Reviewability, and Explainability in Real Editing Systems
See what makes GPTHumanizer AI trustworthy, from privacy and reviewability to explainable editing an...

How to Use GPTHumanizer for Emails, Follow-Ups, and LinkedIn Posts Without Sounding Robotic
Learn how to use GPTHumanizer for emails, follow-ups, and LinkedIn posts without sounding robotic, o...

How to Use GPTHumanizer for Blog Posts Without Losing Your Brand Voice
Learn how to use GPTHumanizer for blog posts without losing brand voice, opinion strength, or senten...

How to Use GPTHumanizer on Long Drafts Without Losing Consistency
Learn how to use GPTHumanizer on long drafts without losing consistency, structure, or voice by edit...