How Academic Journals Screen for AI: A Guide for Researchers
Summary
In 2026, most academic journals screen for AI by combining policy compliance checks, generally for disclosure, with standard integrity scans, similarity, citations, and images, and, of course, human editorial judgment. There is no singular “AI detector score.” When something seems a little off, editors ask for clarification or evidence. The ultimate safe play is to make your manuscript auditable: specific methods, verifiable references, consistent voice, and the occasional admission — when required — of AI usage.
Let’s be real for a second. If you’re anxious about getting flagged, you should know that journals don’t have a magic “Gotcha!” button that just instantly detects AI.
It’s not a cat-and-mouse game where they are looking to catch you red-handed. They’re doing a process consisting of checking policy compliance, running standard integrity scans (e.g., referencing or images), and, most importantly, the human editors reading it. They simply only go on a “panic button” when they see something looks a little messed up or risky.
So stop consciously trying to “sound more human.” The best play is to make your manuscript auditable: specific methods, verifiable references, consistent voice, and the occasional admission when required of AI.
What journals mean by “AI screening”
Think of AI screening like risk triage, not a courtroom drama.
That's really what editors are doing: They just want to know “Can I trust this to send to a reviewer?” They're not looking for AI in and of itself; they're looking for policy violations (like not admitting you used ChatGPT) or red flags for integrity (like hallucinated citations).
If you want context for the ethics and workflow disruptions happening in this space right now, check out this academic AI detection and workflow breakdown, which explains why this is all so messy.
Think of screening as a risk management exercise, not a style battle. Your job is not to try and sound “less AI,” but to be accountable so that they can trust it is safe to publish.
The typical screening pipeline from submission to decision
Most journals stick to a pretty standard routine: robots first, humans second, reviewers last.
The “AI panic” usually happens when a bot flags a policy issue (“Hey, did they disclose this?”) or when the writing just feels… off.
Here’s the flow I see most often (it rhymes across most publishers):
Submission → Admin checks → Similarity/reference checks → Editorial read → Policy compliance check → Peer review → Final decision
Screening layer | What it’s trying to catch | Common signals editors notice | Ethical way to reduce risk |
Policy compliance | Hiding AI use, authorship issues | Missing notes, vague sentences | Add a clear AI-use note if required |
Similarity checks | Copy/paste, recycled text | High overlap, template-y prose | Paraphrase your own ideas, don’t outsource thinking |
Reference integrity | Fake / mixed-up citations | Citations that don’t match the text | Double-check every citation against the actual PDF |
Methods/results coherence | “Fluent but empty” science | Shiny claims, weak methods | Be specific: parameters, datasets, limits |
Editorial judgment | “Do I trust this?” | Voice changes, generic framing | Make it yours: explain trade-offs and choices |
Basically, the process is a funnel where no single tool makes the final call. Editors only escalate when trust signals get weird, so your best defense is simply writing a paper that’s easy for them to verify quickly.
Detectors mostly read style, not reasoning
Here is my blunt take: AI detection is basically style recognition, not logic checks.
Detectors look for patterns—predictability, boring sentence structures, that “too smooth” vibe. But here’s the thing: you can write brilliant logic (or terrible logic) in any style.
That’s why the research community keeps finding hard limits: performance drops when you heavily edit or mix human + model writing, and there are statistical overlaps that make perfect classification unrealistic, as discussed in this reliable AI-text detection study.
Remember that detectors judge patterns rather than truth. Editors are smarter than the software—they care about where your data came from, not just the "score," so treat those numbers as helpful signals rather than a final verdict.
What triggers manual follow-up and how to avoid it
If your paper gets flagged, it’s usually because something else smells fishy. Editors don’t have time to chase ghosts—they chase inconsistencies.
Here are the triggers I see all the time:
Fake references: citations that don’t match the claims (or don’t exist).
Generic fluff: a literature review that reads like a Wikipedia summary.
Thin methods: huge confidence in results, but zero detail on how you got there.
Tone whiplash: intro sounds like a press release, methods sound like a robot.
Perfect grammar, zero meaning: it reads smoothly, but says nothing precise.
Want to actually fix this? Try these:
Write down your choices: “We chose X over Y because…”
Get specific: add the ugly details—parameters, code, what didn’t work.
Save your drafts: keep version history and messy notes. It’s boring until it saves your career.
Inconsistency is the real enemy here, not how polished your writing is. Specific details beat "sounding natural" every time, and keeping your documentation is the best insurance policy you can have.
How publisher policies shape “acceptable AI use”
Every publisher is different, but one rule stays the same: humans are on the hook.
Most policies are fine with you using AI to polish your English, but they want you to admit it if you used it to generate ideas or text blocks.
Springer is pretty explicit that LLMs can’t be authors, and it draws lines around what needs documentation in its Artificial Intelligence (AI) editorial policy.
Here’s the cheat sheet:
Did AI change the meaning or write a whole section? Disclose it.
Did AI fix grammar and clarity? Some journals treat this like a spell checker—still, don’t guess. Check the journal’s instructions.
These policies aren't "anti-AI," they're just about accountability. Don't be ashamed to disclose your tools—it shows responsibility—and seriously, just read and follow the specific journal instructions.
When an AI detector helps before submission
I’m not saying detectors are useless. I’m saying don’t use them as a lie detector.
Used correctly, a detector is a great sanity check: “Does this section sound weirdly generic or overly uniform?” If yes, go back and add specifics. Make it sound like you made real research decisions.
If you want a quick check, the GPTHumanizer AI detector can be a useful input for spotting sections that might make an editor raise an eyebrow (and yes—make sure you’re on the .ai domain, because there are similarly named tools out there).
The honest downside?
Detectors are noisy, especially for technical writing or non-native English. Don’t optimize for a “human score.” Optimize for clarity.
Use detectors as a pre-flight check to fix clarity, not to prove your innocence or game the system. Never rely on a single score to tell you if a paper is good; use it to improve your writing.
What to do if a journal questions your AI use
First off: don’t panic. A question isn’t a rejection—it’s just them asking for reassurance.
A clean response usually looks like this:
Be direct about what tools you used and why (yes, that includes GPT-5.2-level tools).
Show proof of human authorship (drafts, notes, tracked changes).
Fix the objective stuff (bad citations, vague claims, missing details).
Update your disclosure if you forgot it the first time.
Publishers are pushing harder because they see lots of undeclared AI text; Nature reported that less than 25% of authors disclosed AI use despite disclosure requirements.
If they ask questions, be transparent and show your docs. Focus on fixing real problems like citations rather than just wording, and assume the editor just wants to be confident in your work, not fight you.
The Final: Is it worth obsessing over sounding human?
If you were to take one thing from this: journals are not grading your vibe. They’re grading your accountability.
You may have a detector as part of your process, but it’s almost never the lone gunner on the decision. What really decides is whether your manuscript looks like defensible, verifiable work.
So yeah, write well. But also, write traceably. Show your work, keep your logs, and do your right duty on AI disclosure when it’s in the policy. That’s the approach that survives 2026 screening, peer review, and whatever else comes next.
FAQ: Academic journal AI screening
Q: How do academic journals screen for AI-generated text in 2026?
A: Academic journals typically use a layered workflow: disclosure/policy checks, integrity scans (similarity and references), and human editorial review—then they investigate only if inconsistencies suggest elevated integrity risk.
Q: Is an AI detector score the final verdict in academic journal AI screening?
A: An AI detector score is rarely treated as final proof; reputable journals use it as a weak signal and rely more on documentation, policy compliance, and whether citations, methods, and claims actually hold up.
Q: What must be disclosed about using ChatGPT or GPT-5.2 tools in a journal manuscript?
A: If an LLM meaningfully generated or rewrote content, many journals expect you to name the tool, describe what it did, and confirm the authors remain responsible for accuracy, originality, and citations.
Q: Why do journal submissions get flagged for AI concerns?
A: Journal submissions are most often flagged because of mismatched citations, generic sections, thin methods, or inconsistent voice—not because the prose sounds polished or grammatically perfect.
Q: Can a journal reject a paper for using AI for grammar editing or translation?
A: Many journals allow limited AI-assisted language polishing, but rejection risk rises when use violates disclosure rules or introduces integrity issues like incorrect citations, fabricated references, or unverifiable claims.
Q: Does the GPTHumanizer AI detector help researchers before journal submission?
A: It can help as a sanity check to highlight overly generic passages, but it should not replace verifying citations, adding methodological detail, keeping draft history, and following the target journal’s disclosure policy.
Q: What should authors do when a journal asks whether AI was used in a manuscript?
A: Authors should answer directly with what tools were used and why, share draft history if needed, correct any objective problems (citations/method detail), and update disclosures so editors can trust the work’s provenance.

Related Articles
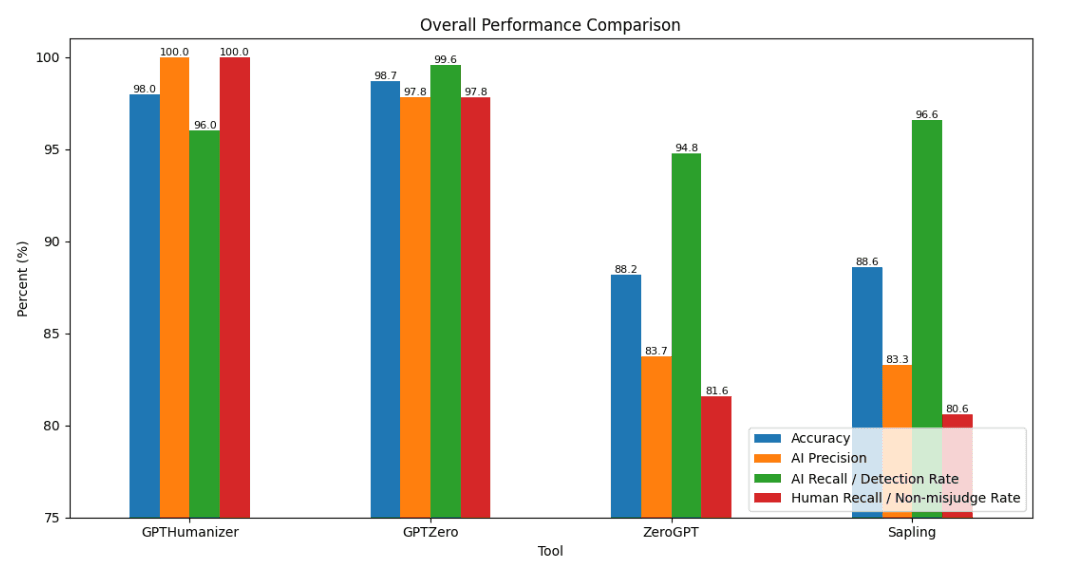
2026 AI Detector Benchmark: Can You Really Trust AI Detectors?
We tested GPTHumanizer, GPTZero, ZeroGPT, and Sapling on 1,000 English texts to compare AI detection...

GPTinf AI Detector Review: Is Its Checker Actually Reliable?
GPTinf AI Detector review with real tests on AI text, human writing, GPTinf output, GPTHumanizer AI ...