2026 AI Detector Benchmark: Can You Really Trust AI Detectors?
Summary
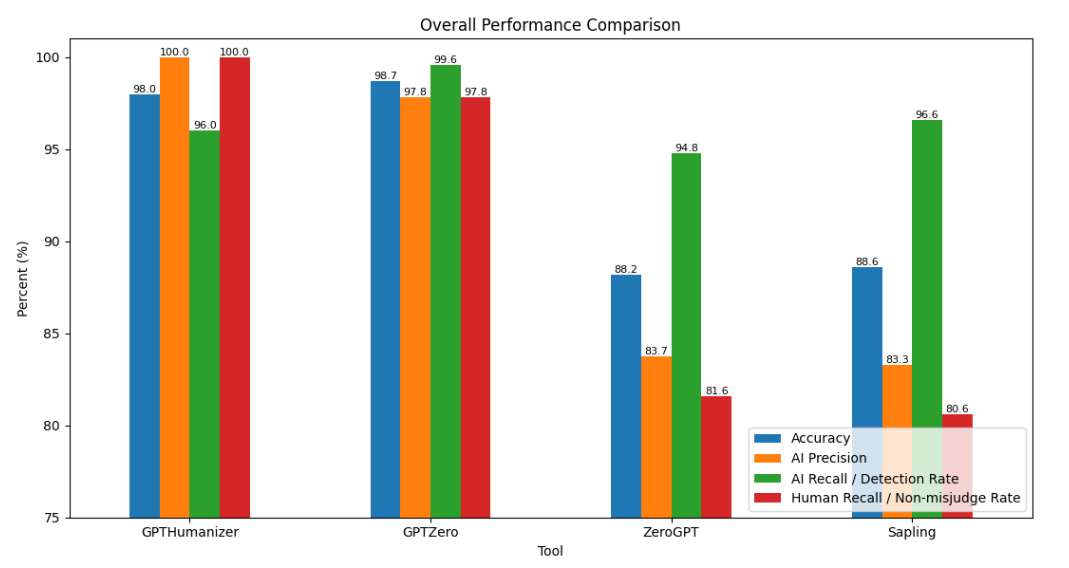
This 2026 AI detector benchmark tested GPTHumanizer, GPTZero, ZeroGPT, and Sapling on 1,000 English texts to compare overall accuracy, AI detection rate, human false positive rate, and AI miss rate.
The test dataset included 500 human-written texts and 500 AI-generated texts from 13 different AI models. Text length was controlled across three ranges: 50–200 words, 200–500 words, and 500–1,000 words.
The main finding is that raw accuracy alone does not tell the full story. GPTZero achieved the highest overall accuracy at 98.70% and the strongest AI detection rate at 99.60%, but it also misclassified 2.20% of human-written texts as AI.
GPTHumanizer achieved 98.00% overall accuracy and had the lowest human false positive risk in this benchmark, with 0 out of 500 human-written texts incorrectly flagged as AI. This makes it the strongest option in the test for use cases where false accusations matter, such as schools, universities, publishing teams, and institutional review workflows.
ZeroGPT and Sapling both detected many AI-generated texts, but they produced much higher human false positive rates. ZeroGPT incorrectly flagged 18.40% of human-written texts as AI, while Sapling incorrectly flagged 19.40%.
The benchmark also shows that short AI texts are harder to detect. In the 50–200 word range, GPTHumanizer missed more AI-generated samples than GPTZero, but it still maintained a 0.00% human false positive rate. This reflects a more conservative detection profile: it may miss some uncertain AI text, but it avoids wrongly accusing human writers in this dataset.
The practical conclusion is simple: the most trustworthy AI detector is not always the one that flags the most AI text. For high-stakes use, human false positive rate should be treated as one of the most important trust metrics.
Key Findings
| AI Detector | Overall Accuracy | AI Detection Rate | Human False Positive Rate | AI Miss Rate | Main Takeaway |
|---|---|---|---|---|---|
GPTHumanizer | 98.00% | 96.00% | 0.00% | 4.00% | Best for reducing false accusations against human writers |
GPTZero | 98.70% | 99.60% | 2.20% | 0.40% | Best for maximum AI recall |
ZeroGPT | 88.20% | 94.80% | 18.40% | 5.20% | High human false positive risk |
Sapling | 88.60% | 96.60% | 19.40% | 3.40% | Highest human misclassification risk in this benchmark |
AI detectors are now used in schools, universities, content teams, SEO workflows, publishing platforms, and internal compliance reviews. But one question is becoming more important than ever:
Can you actually trust an AI detector?
The answer is more complicated than simply asking which detector has the highest accuracy. In real-world AI detection, the biggest risk is not always missing some AI-written text. The bigger danger is falsely accusing human-written text of being AI-generated.
That is why this benchmark focuses not only on overall accuracy, but also on human false positive rate: the percentage of real human texts incorrectly flagged as AI.
In this 2026 benchmark, tests were conducted in May 14th 2026. In this benchmark, we tested four AI detection tools:
GPTHumanizer
GPTZero
ZeroGPT
Sapling
Each tool was tested on 1,000 English texts, including:
500 human-written texts sourced from PILE SMALL
500 AI-generated texts from 13 different AI models
The word-count distribution was controlled across both human and AI datasets:
50-200 words: 30%
200-500 words: 40%
500-1000 words: 30%
This gives a more balanced view of how each AI detector performs across short, medium, and long English texts.
To make the benchmark easier to audit, we also published the full 2026 AI Detector Benchmark on GitHub, including the benchmark input data, evaluation scripts, aggregate metrics, and links to the complete per-item detector outputs. This allows readers to review the methodology behind the summary results instead of relying only on the tables in this article.
Key Takeaway
The benchmark shows a clear pattern:
GPTZero achieved the highest overall accuracy, but GPTHumanizer delivered the lowest institutional risk by producing zero human false positives.
GPTHumanizer reached 98.00% overall accuracy, with 0 out of 500 human texts misclassified as AI. In other words, across 500 human-written samples from multiple domains, GPTHumanizer showed no false accusation risk in this benchmark.
This matters because in schools, universities, companies, and publishing environments, a false positive is not just a statistical error. It can become a credibility issue, a disciplinary issue, or a serious trust problem.
If you want to check your own text after reading the benchmark, you can test it with the GPTHumanizer AI Detector and treat the result as a review signal rather than final proof.
Benchmark Summary
AI Detector | Overall Accuracy | AI Detection Rate | Human False Positive Rate | AI Miss Rate |
GPTHumanizer | 98.00% | 96.00% | 0.00% | 4.00% |
GPTZero | 98.70% | 99.60% | 2.20% | 0.40% |
ZeroGPT | 88.20% | 94.80% | 18.40% | 5.20% |
Sapling | 88.60% | 96.60% | 19.40% | 3.40% |
GPTZero performed very strongly overall, with the highest accuracy and highest AI recall. However, it still misclassified 11 human-written texts as AI out of 499 evaluable human samples.
ZeroGPT and Sapling detected many AI texts, but both produced high human false positive rates. ZeroGPT incorrectly flagged 92 out of 500 human texts as AI, while Sapling incorrectly flagged 97 out of 500 human texts as AI.
That difference is not small. It fundamentally changes how safe each detector is for real-world use.
Why Human False Positive Rate Matters More Than Most People Think
Many AI detector comparisons focus on one number: accuracy.
But accuracy alone can be misleading.
For example, a detector can look strong if it aggressively labels many texts as AI. That may increase AI recall, but it can also create a dangerous side effect: human texts get falsely accused.
In AI detection, this is called a false positive.
A false positive means:
A real human-written text is incorrectly classified as AI-generated.
For schools, this is especially serious. A student could be accused of using AI even when they wrote the assignment themselves. For publishers, it could damage an author’s reputation. For companies, it could create unnecessary internal review problems.
That is why human false positive rate is one of the most important trust metrics in the AI detection industry.
A detector should not simply ask:
“How many AI texts can I catch?”
It should also ask:
“How many human writers might I unfairly accuse?”
By that standard, GPTHumanizer performed extremely well in this benchmark.
GPTHumanizer: Strong Accuracy With Zero Human False Positives
GPTHumanizer achieved:
98.00% overall accuracy
96.00% AI detection rate
100.00% human recall
0.00% human false positive rate
0 human texts wrongly flagged as AI
This is the most important result in the benchmark.
Across 500 human-written texts from multiple domains, GPTHumanizer did not misclassify a single human text as AI.
That makes GPTHumanizer especially valuable for use cases where fairness and risk control matter, including:
Schools and universities
Student writing review
Academic integrity workflows
Publishing and editorial review
SEO content quality checks
Enterprise document screening
Human writer verification
GPTHumanizer is slightly more conservative than GPTZero when detecting AI-generated text. It missed 20 out of 500 AI texts, meaning its AI false negative rate was 4.00%.
However, this is a reasonable trade-off.
In real-world AI detection, wrongly labeling a human as AI is often more damaging than letting a small percentage of AI text pass as human. A missed AI text may require another review. But a false accusation against a real person can cause reputational, academic, or institutional harm.
This is where GPTHumanizer’s benchmark profile becomes especially strong:
low-risk, human-safe, and institution-friendly.
Short AI Texts Are Harder to Detect
One important detail from the benchmark is GPTHumanizer’s performance on short AI texts.
In the 50-200 word range, GPTHumanizer detected 136 out of 150 AI texts and missed 14 out of 150 AI texts. That means short AI texts were misclassified as human at a rate of about 9.33%.
This is worth acknowledging honestly.
Short AI texts are harder for almost every detector because there is less linguistic evidence to analyze. A 100-word paragraph may not contain enough stylistic patterns, repetition, structure, or probability signals for a detector to make a confident judgment.
But here is the key point:
GPTHumanizer’s short-text trade-off is conservative.
It is more willing to avoid accusing human text incorrectly, even if that means some short AI texts may be classified as human.
For schools and institutions, this matters. In high-stakes settings, a detector that avoids false accusations can be more responsible than one that aggressively flags uncertain text as AI.
GPTZero: Excellent AI Recall, But Some Human False Positives
GPTZero delivered the strongest overall performance in raw accuracy:
98.70% overall accuracy
99.60% AI detection rate
2.20% human false positive rate
0.40% AI miss rate
GPTZero detected almost all AI-generated texts, missing only 2 out of 499 evaluable AI samples.
That makes GPTZero highly effective if the goal is to catch as much AI-generated text as possible.
However, GPTZero also incorrectly flagged 11 human-written texts as AI.
A 2.20% false positive rate may sound low, but in real institutional use, it can become significant. If a school checks 10,000 human-written essays, a 2.20% false positive rate could mean around 220 human-written essays are incorrectly flagged as AI.
That does not mean GPTZero is weak. In fact, it performed very well. But compared with GPTHumanizer, GPTZero takes a more aggressive detection approach.
The trade-off is clear:
GPTZero catches slightly more AI
GPTHumanizer avoids false accusations more effectively
For institutions, that difference matters.
ZeroGPT: High Human False Positive Risk
ZeroGPT achieved:
88.20% overall accuracy
94.80% AI detection rate
18.40% human false positive rate
5.20% AI miss rate
The biggest concern is its human false positive rate.
ZeroGPT misclassified 92 out of 500 human-written texts as AI.
That means nearly 1 in 5 human texts was incorrectly flagged.
This is a serious issue for any AI detector used in education, publishing, or professional review. Even if ZeroGPT can detect many AI texts, its tendency to over-flag human writing makes it risky as a standalone decision tool.
The problem is especially visible in formal or structured human writing. Some human-written texts naturally look polished, consistent, and predictable. Legal writing, academic abstracts, business documents, and technical explanations can all appear “AI-like” to aggressive detectors.
A reliable AI detector needs to distinguish between:
AI-generated text
polished human writing
edited human writing
structured professional writing
This is where binary or overly aggressive detection can become dangerous.
Sapling: Good AI Detection, But Highest Human Misclassification Risk
Sapling achieved:
88.60% overall accuracy
96.60% AI detection rate
19.40% human false positive rate
3.40% AI miss rate
Sapling detected AI text reasonably well, but it produced the highest human false positive rate among the four tools.
It incorrectly flagged 97 out of 500 human-written texts as AI.
This means Sapling’s benchmark profile is highly aggressive. It catches many AI texts, but the cost is high: many real human texts are also labeled as AI.
In this benchmark, Sapling uses an AI score, and we treated texts with AI score > 50 as AI. This makes it different from multi-class detectors that provide more nuanced classifications.
The issue with score-only detection is that a single threshold can oversimplify complex writing patterns. Human writing is not always messy, informal, or unpredictable. Many real human texts are polished, structured, and professional.
That is why a high AI score does not always mean a text was actually generated by AI.
Multi-Class AI Detection vs Score-Based AI Detection
Not all AI detectors classify text in the same way.
In this benchmark, the tools differ not only in accuracy, but also in output structure.
GPTHumanizer and GPTZero are more nuanced AI detectors. They are designed around multiple categories such as:
Human
Polished
Humanized
AI
This type of classification is useful because real-world writing is not always simply “human” or “AI.” A text may be human-written but polished. It may be AI-generated but heavily edited. It may contain mixed signals.
ZeroGPT uses a simpler classification structure, including:
Human
Mix
AI
This gives some intermediate signal, but the benchmark shows it still produced a high human false positive rate.
Sapling is primarily score-based, using an AI score. In this benchmark, we treated score > 50 as AI. This makes the detector easier to interpret numerically, but also more sensitive to threshold decisions.
The broader lesson is simple:
AI detection should not be treated as a pure binary problem.
The more nuanced the detector, the easier it becomes to separate actual AI generation from polished human writing.
Performance by Word Count
Text length had a major impact on detector performance.
50-200 Words
AI Detector | Accuracy | Human False Positive Rate | AI Miss Rate |
GPTHumanizer | 95.33% | 0.00% | 9.33% |
GPTZero | 96.67% | 6.00% | 0.67% |
ZeroGPT | 85.33% | 20.67% | 8.67% |
Sapling | 85.33% | 24.67% | 4.67% |
Short text is clearly the hardest category.
GPTHumanizer’s main weakness appears here: it missed 14 out of 150 short AI texts, creating a short AI miss rate of about 9.33%.
However, it still maintained 0% human false positives in this short-text range. That means it did not wrongly accuse any short human text of being AI.
GPTZero was stronger at catching short AI text, but its human false positive rate rose to 6.00%. ZeroGPT and Sapling were much riskier, incorrectly flagging more than 20% of short human texts as AI.
200-500 Words
AI Detector | Accuracy | Human False Positive Rate | AI Miss Rate |
GPTHumanizer | 99.00% | 0.00% | 2.00% |
GPTZero | 99.25% | 1.00% | 0.50% |
ZeroGPT | 91.00% | 17.50% | 0.50% |
Sapling | 89.25% | 18.50% | 3.00% |
In the 200–500 word range, GPTHumanizer and GPTZero both performed extremely well.
GPTHumanizer again had 0% human false positives, while GPTZero had a small 1.00% human false positive rate.
ZeroGPT and Sapling continued to show high human misclassification risk.
500-1000 Words
AI Detector | Accuracy | Human False Positive Rate | AI Miss Rate |
GPTHumanizer | 99.33% | 0.00% | 1.33% |
GPTZero | 100.00% | 0.00% | 0.00% |
ZeroGPT | 87.33% | 17.33% | 8.00% |
Sapling | 91.00% | 15.33% | 2.67% |
Longer text gives detectors more signal, so performance generally improves for stronger tools.
GPTHumanizer performed very well on long text, with 99.33% accuracy and 0% human false positives. GPTZero reached 100% accuracy in this bucket, although two samples in the overall GPTZero test were marked as errors.
ZeroGPT and Sapling still showed elevated false positive risk even on longer texts.
The Real Trade-Off: Missing AI vs Mislabeling Humans
Every AI detector has a trade-off.
A detector can be tuned to be more aggressive, catching more AI-generated text. But this often increases the chance of falsely accusing human-written text.
A detector can also be tuned to be more conservative, reducing false accusations. But this may allow some AI-generated texts, especially short ones, to be classified as human.
GPTHumanizer clearly chooses the safer side of this trade-off.
It may miss some AI-generated text, especially in the short-text range, but it dramatically reduces the risk of falsely accusing human writers.
For most serious use cases, this is a responsible design choice.
Why?
Because an AI text mistakenly classified as human can be reviewed again. But a human text wrongly classified as AI can create serious consequences.
In other words:
AI false negatives are a detection limitation. Human false positives are a trust and fairness problem.
That is why GPTHumanizer’s 0% human false positive rate is so important.
Which AI Detector Is Best?
The answer depends on what you value most.
Best for lowest human misclassification risk: GPTHumanizer
GPTHumanizer is the safest choice when false accusations matter. It had zero human false positives across 500 human-written samples.
Best suited for:
Schools
Universities
Human writing verification
Academic integrity review
Institutions that require low-risk AI detection
Content teams that want to avoid mislabeling real writers
Best for maximum AI recall: GPTZero
GPTZero is very strong at catching AI-generated text. It had the highest overall accuracy and the highest AI recall.
Best suited for:
High-recall AI screening
Workflows with human review
Cases where catching AI is prioritized over minimizing every false positive
Higher-risk options: ZeroGPT and Sapling
ZeroGPT and Sapling both showed high human false positive rates. They may still be useful as rough screening tools, but the benchmark suggests they should not be used as final decision tools in high-stakes environments.
Final Verdict: Could You Trust an AI Detector?
Yes, but only if you understand what kind of risk the detector creates.
The most trustworthy AI detector is not necessarily the one that flags the most text as AI. A trustworthy detector should be accurate, but it should also be fair to human writers.
This benchmark shows that GPTHumanizer and GPTZero are significantly stronger than ZeroGPT and Sapling overall. But they have different strengths.
GPTZero is more aggressive and catches more AI.
GPTHumanizer is safer and avoids human false accusations.For schools, institutions, and professional environments, that distinction is critical.
In 2026, the biggest question is not just:
“Can this tool detect AI?”
The better question is:
“Can this tool detect AI without falsely accusing humans?”
Based on this benchmark, GPTHumanizer’s answer is strong:
98% overall accuracy, 96% AI detection rate, and 0% human false positives across 500 human-written texts.
That makes GPTHumanizer one of the lowest-risk AI detectors in this benchmark, especially for organizations that care about fairness, trust, and responsible AI detection.
FAQ
What is the most important metric for an AI detector?
Overall accuracy is useful, but human false positive rate is often more important in real-world use. A false positive means a real human-written text is incorrectly flagged as AI. In schools, universities, publishing, and workplace review, this can create serious consequences.
Which AI detector had the lowest human false positive rate?
GPTHumanizer had the lowest human false positive rate in this benchmark. It misclassified 0 out of 500 human-written texts as AI.
Which AI detector had the highest overall accuracy?
GPTZero had the highest overall accuracy at 98.70%, followed by GPTHumanizer at 98.00%.
Why did GPTHumanizer miss some short AI texts?
Short AI texts are harder to detect because they provide less linguistic evidence. In the 50–200 word range, GPTHumanizer misclassified about 9.33% of AI texts as human. However, it maintained 0% human false positives, which is a safer trade-off for high-stakes settings.
Is an AI text misclassified as human a serious risk?
It can matter, but in many real-world settings it is less harmful than falsely accusing a human writer. A missed AI text can be reviewed again, but a human false positive can unfairly damage a student, writer, or employee.
Should AI detectors be used as final evidence?
No, AI detector should be used as the only evidence in a high-stakes decision. AI detection should support review, not replace judgment. The safest tools are those that combine strong AI detection with very low human false positive rates.

