How Natural Language Generation Works with Transformers
Summary
What is Natural Language Generation (NLG)?
Natural language generation, or NLG, is the branch of AI that produces written language from prompts, structured data, or prior context. In simple terms, it is the part of generative AI responsible for turning internal predictions into sentences people can read.
Generative AI is the broader category of systems that can create text, images, audio, video, and code. NLG sits inside that broader category, focusing specifically on text. That distinction matters because not all generative AI is about language, but NLG is the part that matters most when we talk about AI-written articles, emails, academic drafts, or marketing copy.
Modern NLG does not write the way people do. It predicts likely token sequences from patterns learned during training. That process is powerful, but it also explains why AI text can sound coherent before it sounds genuinely natural.
How Transformer-Based NLG Works
Most modern text generation systems rely on transformer models. Their job is not to retrieve one perfect sentence from memory. Their job is to estimate which token should come next based on the context already on the page.
A simplified version of the process looks like this:
Tokenization
The input is split into smaller units called tokens. These are not always full words. A token can be a word, part of a word, punctuation, or a common text fragment.Embedding and Context Mapping
Each token is converted into a numerical representation so the model can measure relationships across the sequence.Attention
Self-attention helps the model weigh which earlier tokens matter most when predicting what comes next. This is one reason transformers handle context much better than earlier text-generation systems.Next-Token Prediction
The model produces a probability distribution over possible next tokens and selects one based on its decoding setup.
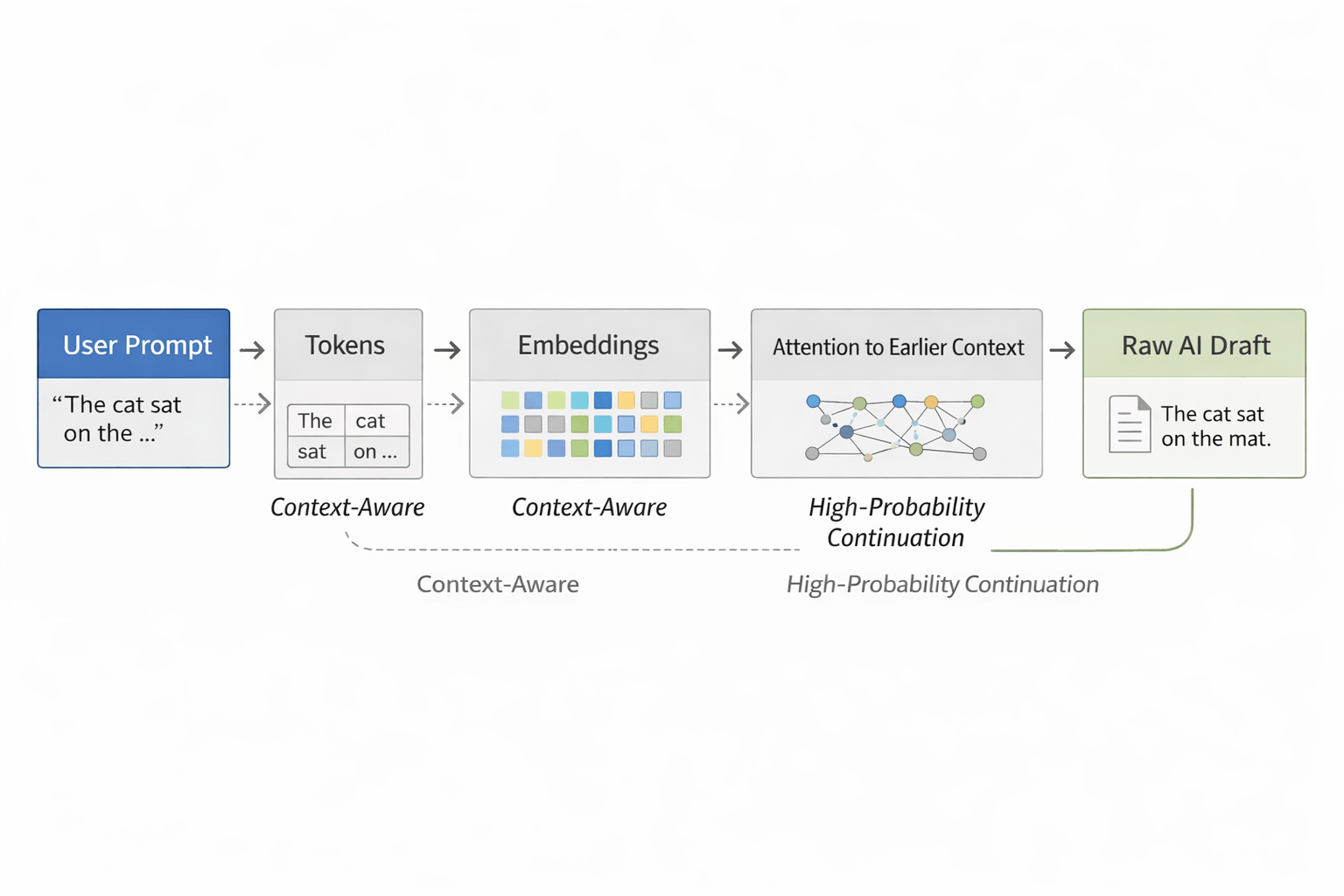
If the prompt is “The cat sat on the…”, the model will assign much higher probability to a likely continuation such as “mat” than to something much less expected. That is one reason raw AI writing often feels smooth but also slightly predictable.
For a deeper look at how text generation systems evolved beyond simpler rewriting methods, see the technical evolution of AI humanizers.
Why AI Text Often Sounds Predictable
AI-generated text usually becomes recognizable not because every sentence is wrong, but because too many sentences are statistically safe. The output tends to favor familiar phrasing, balanced structure, and smooth transitions. That makes it readable, but it can also make it feel overly even.
Two ideas are useful here:
Perplexity describes how predictable a piece of text is to a language model. Lower perplexity usually means the wording is safer and easier to anticipate.
Burstiness describes variation in sentence shape and rhythm. Human writing naturally mixes short lines, long sentences, interruptions, emphasis shifts, and uneven pacing.
That does not mean human writing is random and AI writing is always flat. It means human writing often contains more structural variation, more context-sensitive phrasing, and more irregular rhythm than default model output.
If you want a deeper explanation of those signals, read perplexity and burstiness explained.
How Humanization Changes Syntax Without Changing Meaning
Humanization is not just synonym swapping. Stronger systems work at the sentence-structure level. They may change clause order, vary sentence openings, reduce repetitive transitions, adjust rhythm, and replace generic phrasing with wording that feels more context-aware.
That matters because naturalness usually comes from structure as much as vocabulary. A sentence can keep the same meaning while sounding much more human once its pacing, emphasis, and syntax are rebuilt.
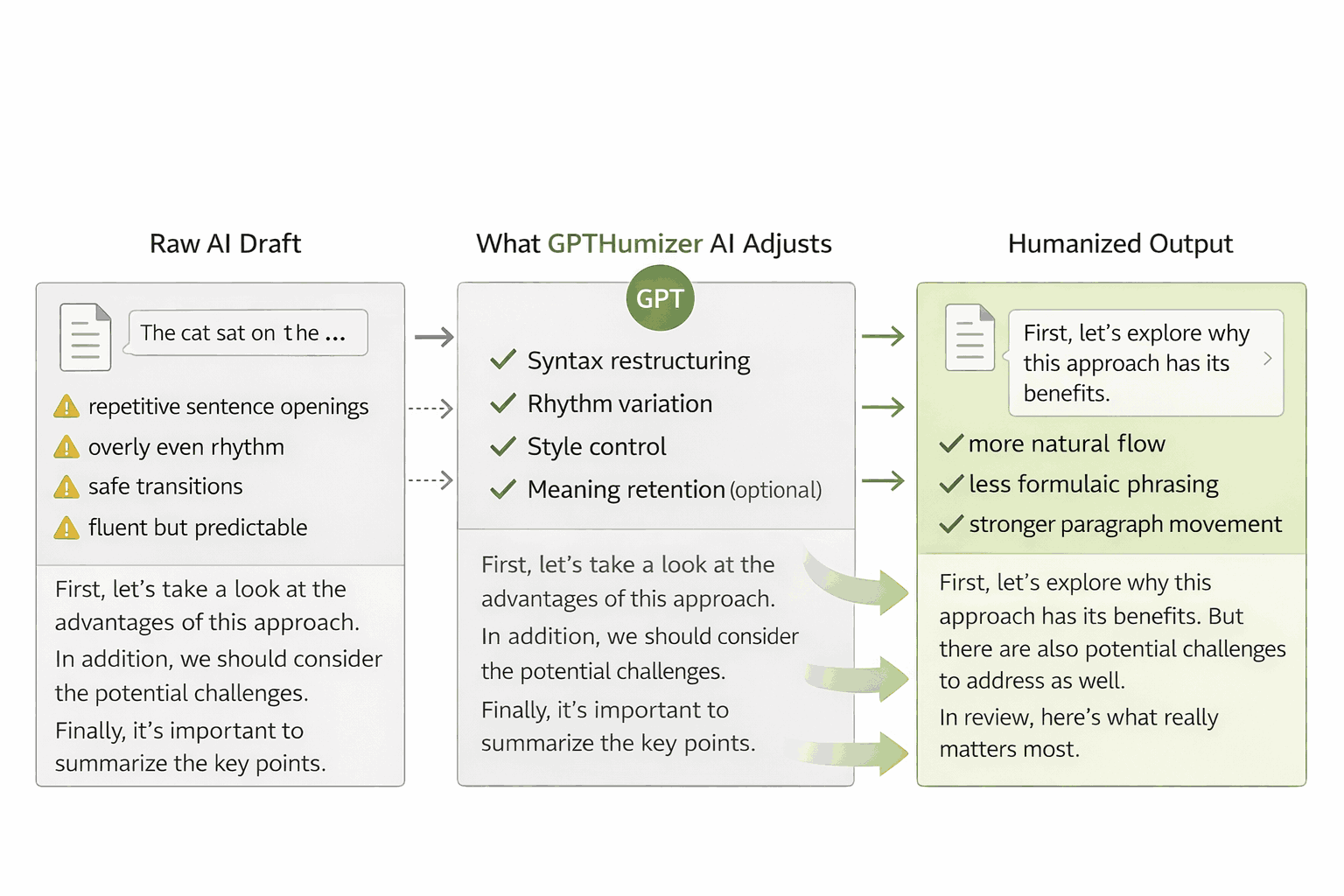
This is also where tools such as GPTHumanizer AI become useful. The goal is not to make text random. The goal is to create more variation while preserving the original point.
To see how this shift connects to newer rewriting approaches, you can also read from dictionary mapping to neural style transfer.
Standard AI Syntax vs. More Human-Like Syntax
Feature | Default AI Output | More Human-Like Output |
|---|---|---|
Sentence rhythm | Even and uniform | More varied and less predictable |
Transitions | Repetitive and orderly | More natural and context-sensitive |
Word choice | Safe and high-frequency | More flexible and situation-aware |
Syntax | Clean but patterned | More dynamic and less formulaic |
Overall feel | Fluent but mechanical | Fluent with more texture |
Syntax Is Only One Part of Natural Writing
A text can sound human at the surface level and still fail at meaning control. That is why syntax alone is not enough.
Strong writing depends on at least three layers working together:
Syntax: how sentences are built
Semantics: whether the intended meaning stays intact
Readability and flow: whether the text feels natural in context
This is also why evaluating AI writing needs more than one signal. A passage may look more varied after rewriting, but the real question is whether it still preserves the original point, reads clearly, and fits the intended audience.
For a deeper look at how these dimensions can be tested together, see building a humanizer evaluation framework.
Why Fluent Text Can Still Feel Machine-Written
Fluency is not the same thing as human-like writing. A passage can be grammatically correct, easy to follow, and still feel artificial if every sentence moves with the same rhythm and uses the same type of phrasing.
This is one reason AI-generated content is often described as polished but generic. The problem is usually not correctness. The problem is pattern density. When structure, transitions, and emphasis all feel too consistent, readers notice the sameness even if they cannot explain it technically.
For that reason, improving AI writing is often less about fixing errors and more about reducing predictability.
Beyond NLG: Other Technical Considerations in AI Humanization
Natural language generation explains how AI produces text, but it is only one part of the broader technical picture. Modern humanization systems also rely on training strategy, evaluation design, privacy handling, inference efficiency, robustness under edge cases, and model transparency.
These factors matter because strong output is not only about sounding more natural. It is also about preserving meaning, staying stable across different inputs, processing text efficiently, and handling user content responsibly. In other words, better AI writing depends not just on generation quality, but on the wider technical systems around it.
This is why the field also connects to topics such as reinforcement learning from human feedback, robustness testing, explainability, privacy protocols, and model efficiency. They are not the main focus of this article, but they help complete the broader technical foundation behind AI humanization.
Conclusion
Natural language generation works by predicting likely token sequences from context, not by reproducing human intention in the way people write. That is why modern AI can generate fluent text at scale while still sounding overly smooth, repetitive, or structurally predictable.
Once you understand that gap, the role of humanization becomes much clearer. The goal is not to make text random. The goal is to introduce better variation, stronger rhythm, and more natural syntax without damaging meaning.
That is also why this topic connects directly to attention mechanisms, perplexity, semantic preservation, and evaluation frameworks. Natural writing is not one signal. It is the result of multiple layers working together.
If you want to test that principle in practice, you can start with GPTHumanizer AI and compare how structural rewriting changes the feel of the same passage.
Frequently Asked Questions (FAQ)
Q: What is natural language generation in simple terms?
A: Natural language generation is the part of AI that turns prompts, data, or prior context into readable text.
Q: How do transformer models generate text?
A: They predict the next token based on the tokens that came before it, using attention to weigh which parts of the context matter most.
Q: Why does AI text often sound repetitive?
A: Because default model output tends to favor high-probability wording, familiar transitions, and more uniform sentence structure.
Q: Is syntax the same as meaning?
A: No. Syntax is about sentence form. Meaning depends on whether the text preserves the original idea accurately and clearly.
Q: What does a humanizer change in AI text?
A: A humanizer usually works on structure, rhythm, transitions, and phrasing so the text feels less patterned and more natural.
Q: Can humanized text still preserve the original message?
A: Yes. Stronger humanization focuses on structural variation while keeping the main meaning, intent, and context intact.

Related Articles

Does StealthWriter Pass GPTZero and Turnitin? Real Test Expectations in 2026
Does StealthWriter pass GPTZero and Turnitin? Learn why StealthWriter’s built-in human score may not...
HIX Bypass Pricing Explained: Is It Worth Paying For in 2026?
A practical look at HIX Bypass pricing, paid-plan value, word limits, refund terms, and whether it i...
I Tested 7 Paid AI Humanizers: Which Ones Are Actually Worth Paying For?
I tested 7 paid AI humanizers to see which tools are worth paying for, which need more testing, and ...
Does Hixbypas Work in 2026? Fast, and Aggressive Modes Tested
Does Hixbypas, or HIX Bypass, actually work? I tested Fast and Aggressive modes to compare rewrite q...